代码块
代码块节点支持在行为流中编写 JavaScript(JS)代码,用于实现复杂或特殊的业务逻辑。
代码块功能强大但需要编程基础,请确保您具备基本的 JavaScript 编程能力后再使用。建议优先考虑使用其他节点类型。
基础流程
添加代码块
在行为流中添加代码块节点。添加后可点击代码块节点修改名称,并在右侧编辑区直接编写 JS 代码。也可点击编辑器右上角”展开”按钮,使用大窗口编辑。
项目上线后,代码块修改并同步到后端将会立刻影响生产环境。为避免风险,建议先克隆项目,在该项目中充分验证和调试代码块。
设置出入参
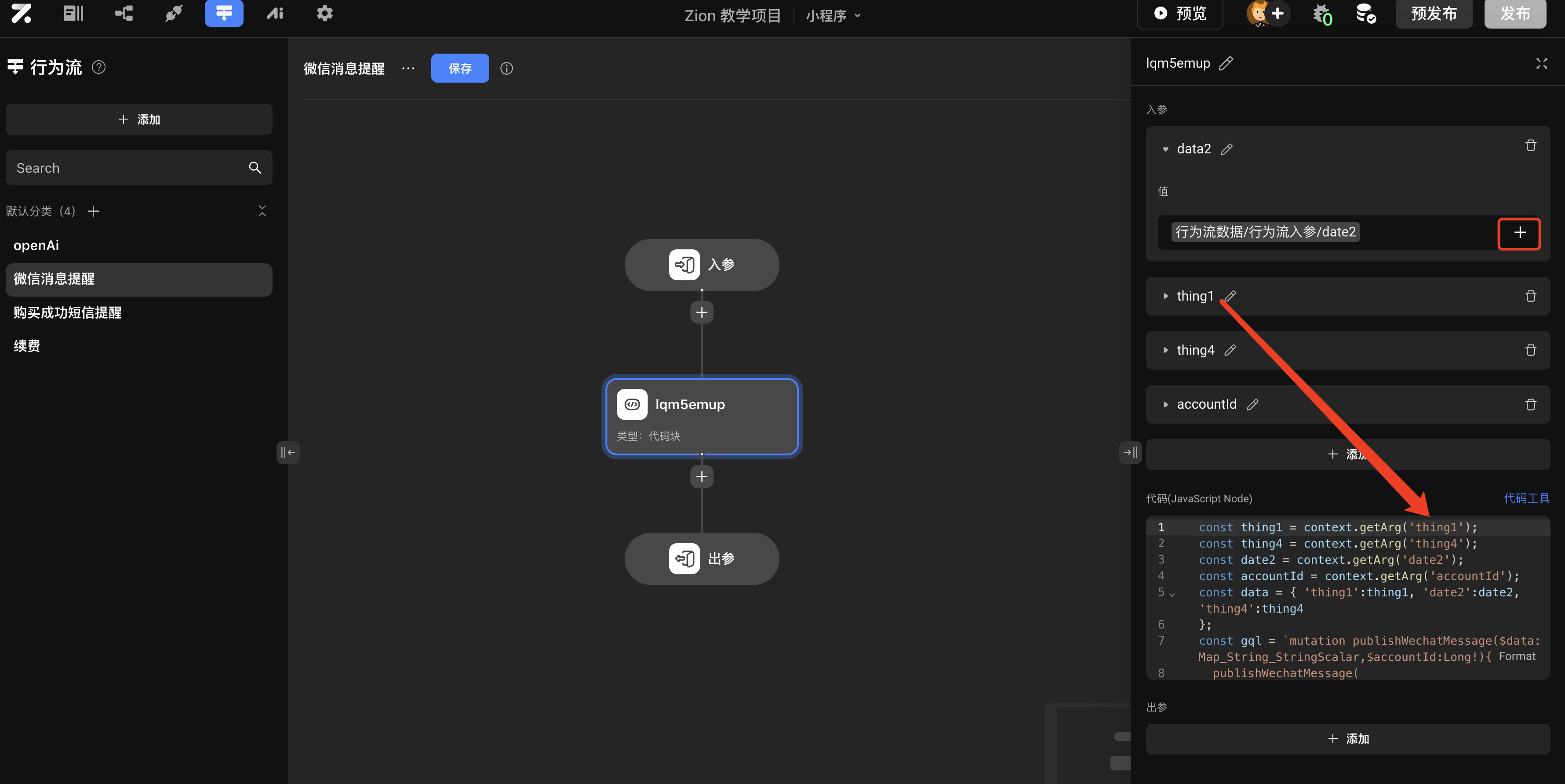
入参配置:
- 在代码块节点上声明入参并绑定值
- 在代码中通过
context.getArg('入参名称')获取入参值
出参配置:
- 如需将参数传递给下游节点,需在代码块节点上声明出参
- 在代码中使用
context.setReturn('出参名称', 参数值)设置出参值
编写代码
环境限制
代码块支持现代 JavaScript 语法,但存在以下限制:
-
不支持依赖 Node.js 环境的方法:
- 不能使用
require()或import加载任何模块。如果需要加载第三方库,参考进阶:使用第三方库 - 不能使用
fetch、XMLHttpRequest或其他库请求网络资源。可使用callThirdPartyApi方法调用已配置好的 API 访问外部服务,或使用runGql调用本项目的后端接口。具体方式查看下一章。 - 无法访问文件系统,不能用
fs模块读取或写入服务器上的任何文件
- 不能使用
-
无法使用浏览器相关 API:
- 不支持
window、document、alert、localStorage、setTimeout等浏览器相关 API
- 不支持
-
不支持异步操作:
- 不支持
async/await异步操作
- 不支持
-
日志输出:
- 不支持
console.log打印日志,请使用context.log替代,并在日志服务中查看
- 不支持
内置方法说明
系统内置了一些实用方法,这些方法都位于 context 对象中:
getArg:获取入参
const value = context.getArg('入参名称');setReturn:设置出参
context.setReturn('出参名称', 参数值);runGql:通过 GraphQL 请求操作数据库
// 1. 定义 gql 语句
const gql = `query findBlogById ($blogId: bigint!){
blog(where: {id:{_eq: $blogId}}) {
id
title
content
}
}`
// 2. 运行 gql
const result = context.runGql(
'findBlogById', // 操作名称,必须和 gql 语句中定义的操作名称一致
gql, // gql 语句
{ blogId: 1 }, // 入参
{ role: 'admin' } // 权限角色,建议固定为 admin
)callThirdPartyApi:调用已配置的 API
context.callThirdPartyApi(
'SCAB61VCBS989410A3', // API 的 ID
{ body: { key: 'key', appkey: 'key', sign: 'sign' } } // API 的入参
);callActionFlow:以同步的方式调用其他行为流
context.callActionFlow(
'f400ac9bc203', // 行为流的 ID
null, // 行为流的版本,为 null 时使用最新版本
{ orderId: 1 }); // 行为流的入参createActionFlowTask:以异步的方式调用其他行为流
context.createActionFlowTask(
'f400ac9bc203', // 行为流的 ID
null, // 行为流的版本,为 null 时使用最新版本
{ orderId: 1 } // 行为流的入参
);getSsoAccountId:获取通过 SSO 登录的用户 ID
context.getSsoAccountId();getSsoUserInfo:获取通过 SSO 登录的用户信息
// 返回值为用户信息 json
context.getSsoUserInfo();wechatSendTemplateMessageWithOpenId:用微信 openId 作为入参发送微信推送消息
// 示例代码
/**
* 直接使用微信 openId 作为入参的方式
*/
const token = 'token'; // 必填
const wechatAppId = 'wechatAppId'; // 非必填,跳转的小程序 App id
const accountOpenId = 'openId'; // 必填,准备发送的消息的 openId
const templateId = 'templateId'; // 必填,用于设置消息的模板 Id
const pagepath = 'pagepath'; // 非必填,小程序页面路径,建议带上参数
const data = {
keyword1: { value: 'aaa' },
clientMsgId: 'uniqueId', // 非必填,10分钟内同 openId 只发一条
url: 'https://aaaa.xxx.xxx' // 非必填,微信跳转链接
};
context.wechatSendTemplateMessageWithOpenId(wechatAppId, accountOpenId, templateId, pagepath, data, clientMsgId, url);uploadMedia:上传图片到服务器
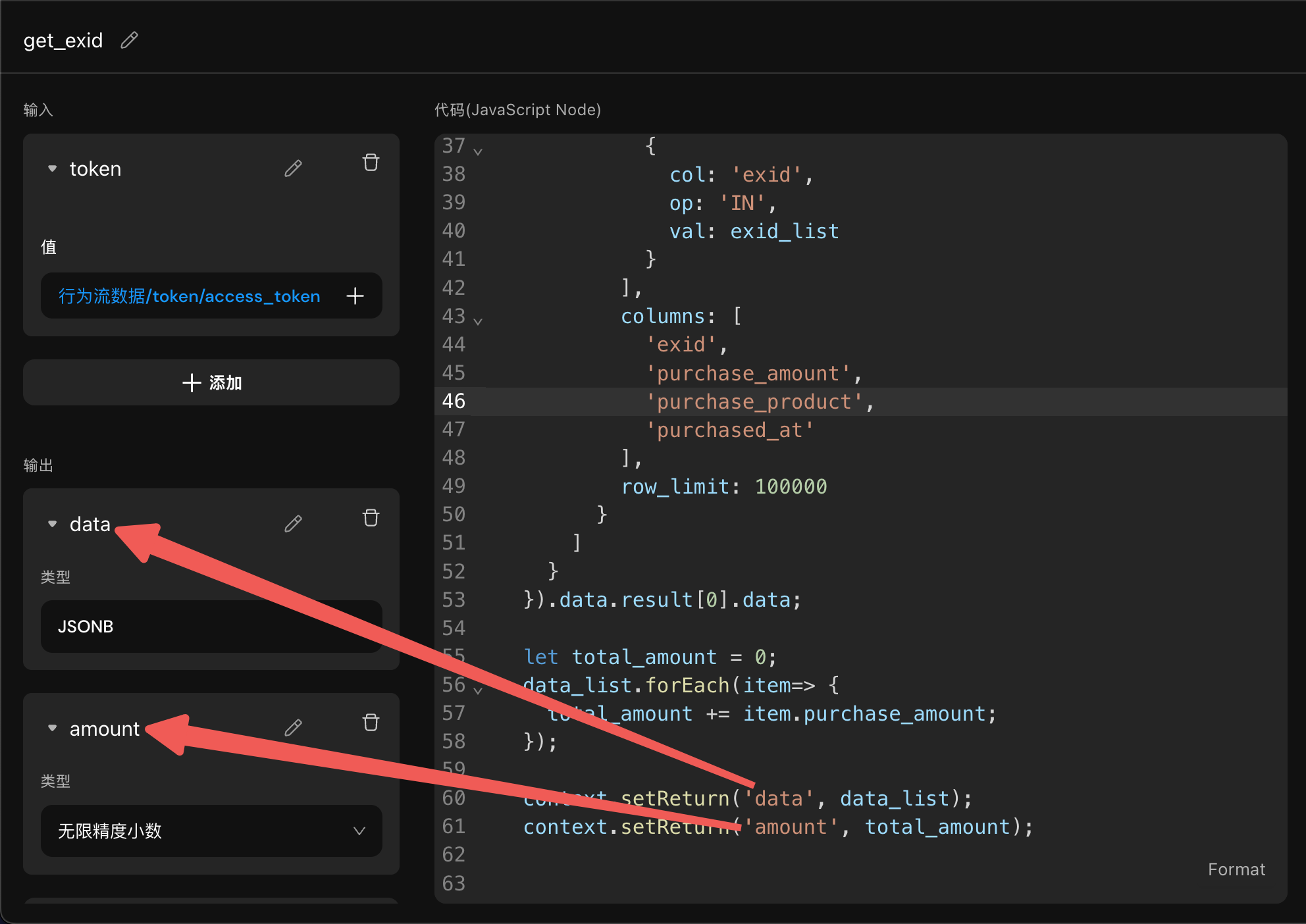
context.uploadMedia(
'https://oss.cyzu.cn/k/file.json?fileKey=2xxx', // 图片地址
{ 'X-cybozu-authorization': 'xsssx' } // 请求需要的headers, 空的时候填{}
);
// 返回值:{mediaType:"IMAGE", id:1020000000000003}以将上传到图片更新到某张表为例:
const xx_id = context.getArg('xx_id') //获取过滤用的表id// 过来的 url 链接
const headers = {}
const media = context.uploadMedia(url, headers) // $url: 图片地址; $headers: 请求需要的headers, 一般都填{},除非你是向非本项目的数据库传文件。
// 返回值举例:{mediaType:"IMAGE", id:1020000000000003}
const imageID = media.id
const gql = `mutation update_image($imageID: bigint,$xx_id:bigint){
update_表名(
_set:{图片字段_id:$imageID}
where:{id:{_eq:$xx_id}})
{
returning{id}
}
}`
context.runGql('update_image', gql, { imageID, xx_id }, { role: 'admin' })进阶:操作数据库
Zion 的接口基于 GraphQL,可以在代码块中使用 runGql 方法操作数据库。
GraphQL 是一种 API 查询语言,本节不涉及 GraphQL 基础知识,如有需要请参考 学习 GraphQL
获取 GraphQL 数据结构(Schema)
Schema 是 GraphQL API 的蓝图,其中包含了所有请求的结构类型、请求参数等。这一步需要借助 API 调试工具来完成,例如:Postman 、Altair 等。下文均以 Postman 为例。
在 Postman 中新建一个请求, 点击左上角类型图标,并选择“GraphQL”分类。
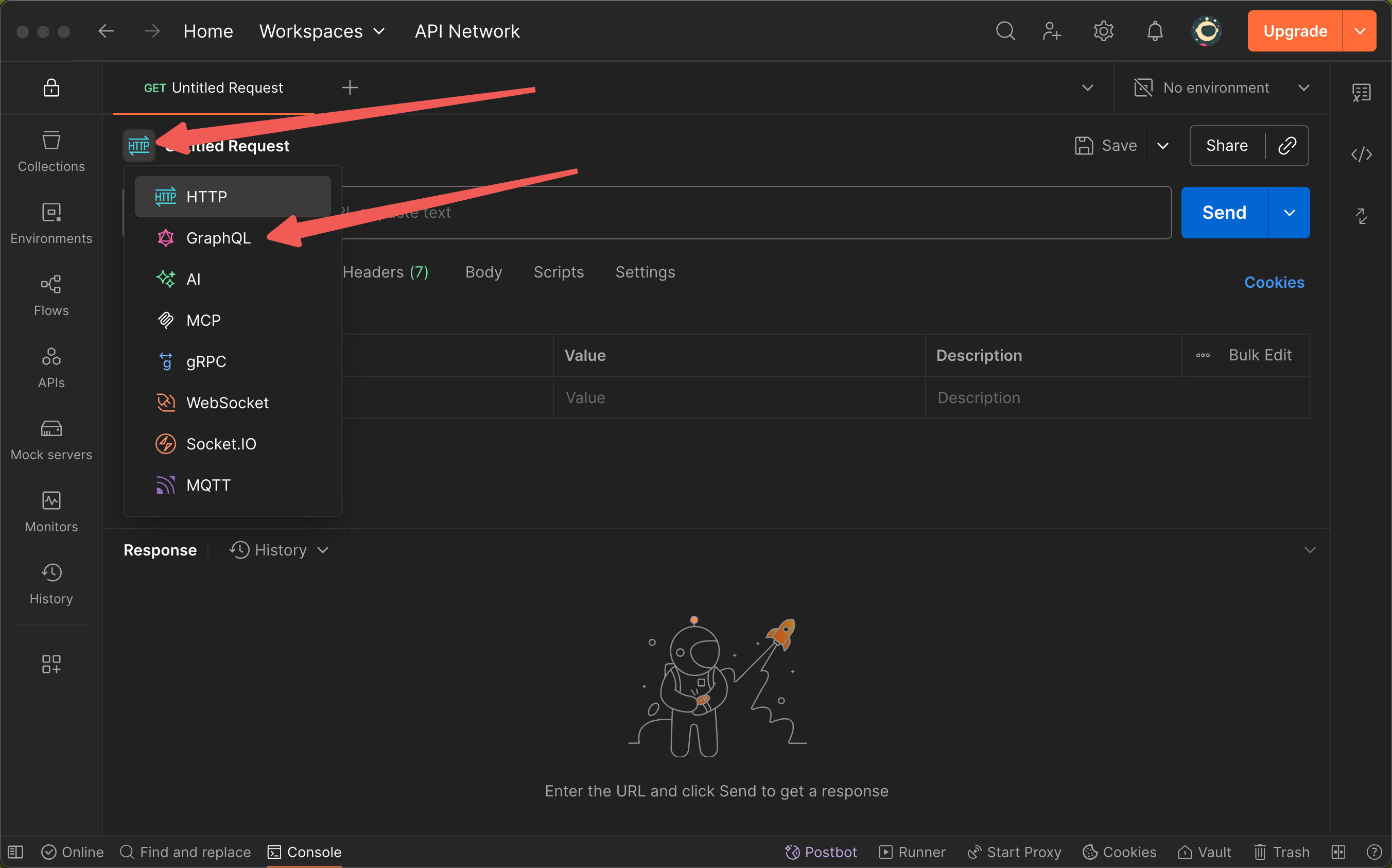
创建后,需要填入项目的后端地址。可进入数据库,按F12进入控制台查看所有请求,其中名称为“graphql-v2”的请求即往项目后端发送的 GraphQL 请求。
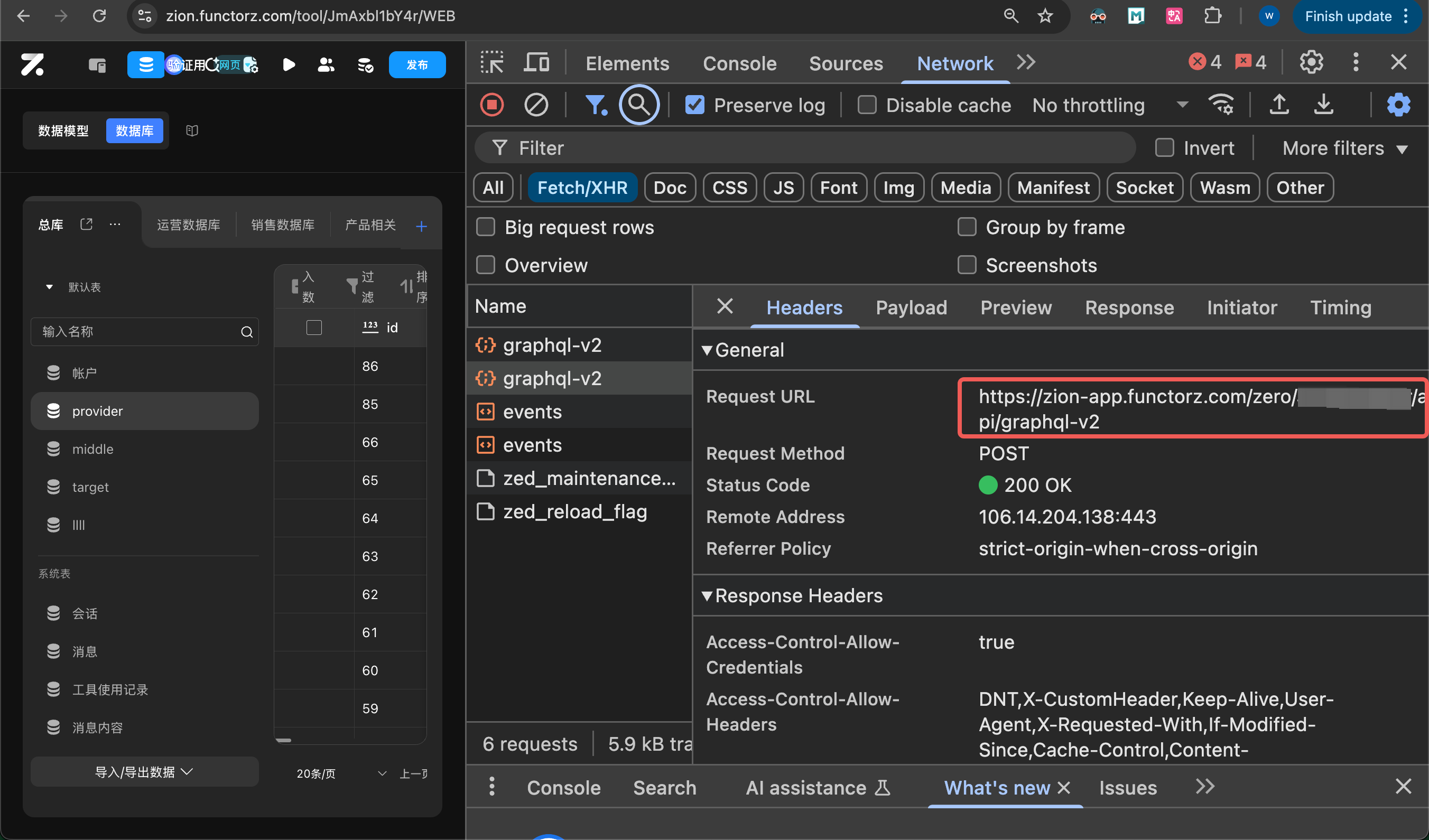
复制该请求的 URL 填入 Postman 后,就会自动获取项目的 GraphQL schema。
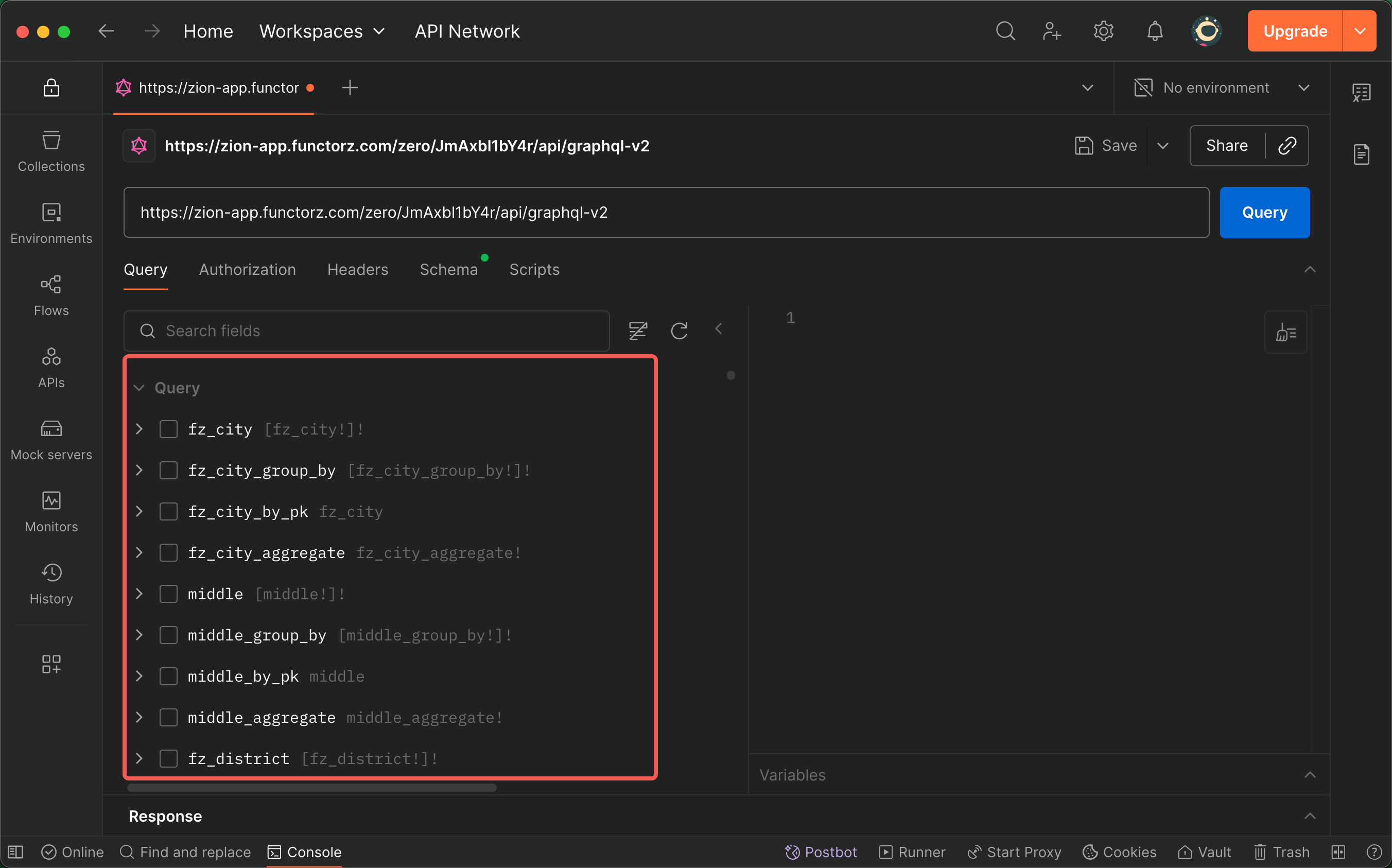
获取 GraphQL 语句
在界面的左侧可以看到接口的结构,选中需要的字段后,右侧就会显示对应的 GraphQL 语句。例如在博客网站中,文章保存在“blog”表中,若需要获取在2025年9月24日前创建的博客的标题和内容,可以按照下列步骤操作。
首先,选中左侧的 blog 表。并添加过滤条件,依次选中“where” -> “created_at” -> “_lt”(表示小于),并填入值“2025-09-24T00:00:00.000+08:00”。
然后,添加返回字段,在左侧依次选中“title”、“content”。
最后,点击“Query”按钮,发送请求。
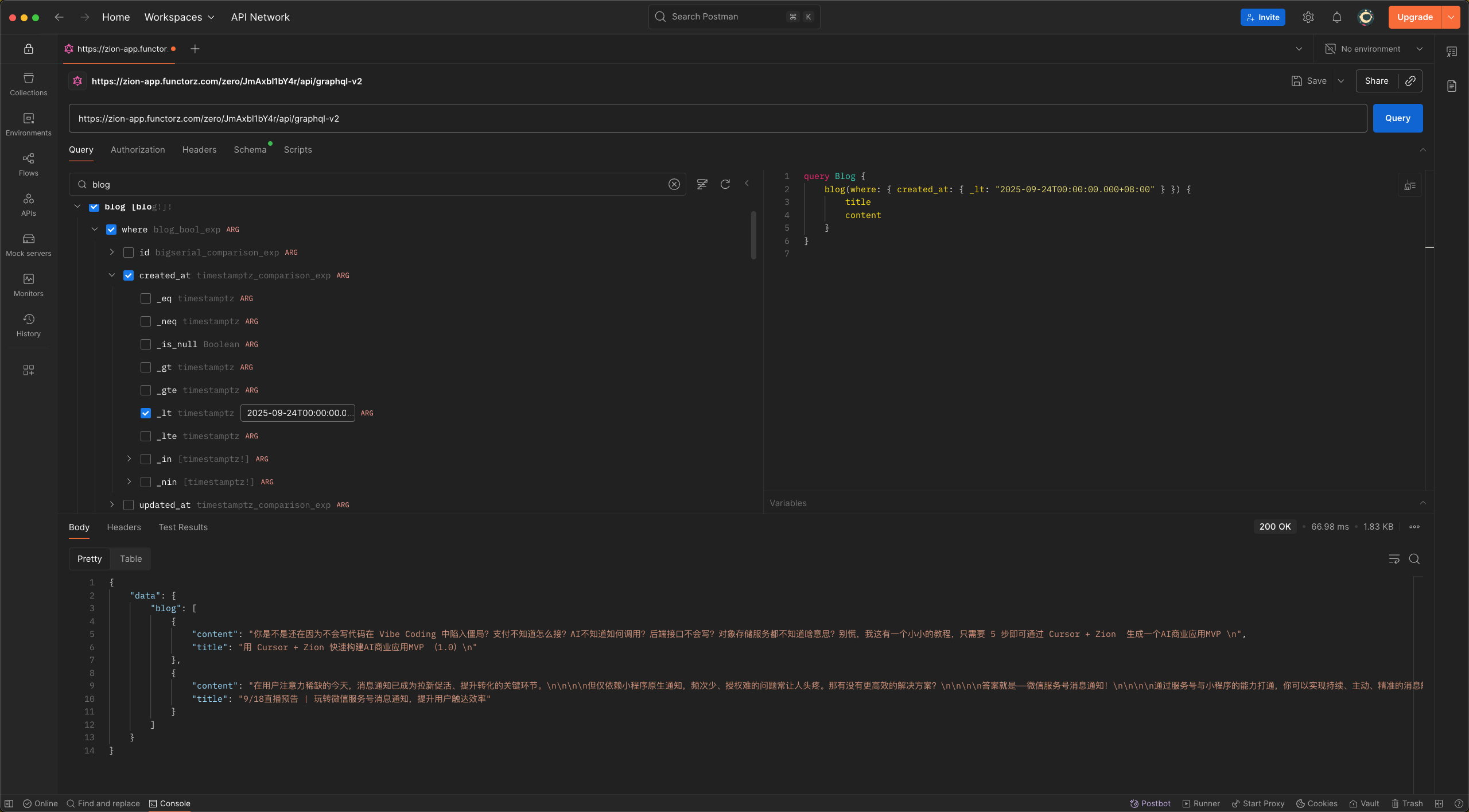
如果需要动态查询,可以在右侧的“Variables”中添加变量。
字段说明:
- where:过滤条件,
- order_by:排序字段
- distinct_on:去重字段
- limit:限制返回数量,表示最多返回多少条数据
- offset:偏移量,表示从第几项开始返回
- id、title、content等:表中的字段
在代码块中运行 GraphQL
在 postman 中调试无误后,就可以将 GraphQL 语句复制到代码块中:
// 1. 定义 gql 语句
const gql = `query findBlogById ($blogId: bigint!){
blog(where: {id:{_eq: $blogId}}) {
title
content
}
}`
// 2. 运行 gql
const result = context.runGql(
'findBlogById',
gql,
{ blogId: 1 },
{ role: 'admin' }
)
// 3. 从结果中提取数据
const status = result.blog[0].status;代码说明
- 定义 gql 语句。字符串类型,里面包含以下内容:
-
操作类型: 在语句的开头指明操作类型,例如 query (查询数据)、mutation (修改数据) 或 subscription (订阅数据变更)。
-
操作名称: 给操作指定一个名称,例如
findBlogById。这个名称在调试和日志记录中非常有用,并且也是 context.runGql 函数的第一个参数。 -
变量定义: 在操作名称后的括号 () 内,你可以定义查询所需要的变量。每个变量都以 $ 开头,后跟变量名和类型,例如
($blogId: bigint!)。 -
查询主体: 在花括号 内,你将指定需要从哪个表或视图查询数据(例如
blog),并列出你希望返回的具体字段(如id,title,content等)。
- 运行 gql
通过调用 context.runGql( operationName , gql , variables , permission ) 函数来执行 gql 语句。该函数接受四个参数:
operationName: 操作名称。必须与你在 gql 语句中定义的操作名称(即 query 或 mutation 关键字后面的名称)完全一致。在此示例中为 findBlogById。
gql: 即上一步中定义的 gql 语句。
variables: 变量对象。这是一个对象,用于传递在 GraphQL 语句中定义的变量。对象的键名需要与 gql 语句中的变量名(去掉 $ 符号)相匹配,值则是你要传入的具体数据。例如 { blogId: 1 } 会将值 1 传递给 GraphQL 中的 $blogId 变量。如果 gql 语句没有定义变量,可以传入一个空对象。
permission: 权限角色。一个用于指定本次操作所用权限角色的对象。这在需要以特定用户角色(如管理员)身份执行操作时非常关键。在示例中,{ role: 'admin' } 表示以“admin”管理员的角色的权限来运行此查询。
- 从结果中提取数据
不同的操作类型有不同的返回数据结构,具体请根据在 postman 调试的返回值来确定。
context.runGql 函数执行成功后,会返回一个包含了查询结果的对象。这个对象的结构与你在 gql 查询主体中定义的结构对应。
例如,在postman 调试时,返回值为:
{
"blog": [
{
"title": "title",
"content": "content"
}
]
}这个对象将会赋值到 result 变量中,根据对象的数据结构,可以用 result.blog[0].title 来提取想要的内容。
进阶:使用第三方库
由于不能使用 require() 或 import 加载任何模块,如果需要使用第三方库(不支持依赖node.js或者浏览器环境的库),需要在电脑上用 Webpack 将第三方库打包成一个文件,然后将文件中的所有代码复制到代码块中。
以下示例以苹果 macOS 系统为例,其他操作系统请根据实际情况调整命令。
创建文件夹
cd /tmp
mkdir webpack-demo
cd webpack-demo初始化项目环境
npm init -y安装 webpack-cli
npm i -g webpack-cli 安装需要导入的包
以 crypto-js 为例
npm i -s crypto-js配置 webpack.config.js
vim webpack.config.js 配置结构如下:
module.exports = {
entry: './node_modules/${moduleName}/${moduleName.js}',
output: {
filename: '${moduleName.js}',
library: '${moduleName}',
libraryTarget: 'var'
}
}一些第三方库的名字中会有 Webpack 不支持的字符,比如本例 crypto-js中的 “-”,此时需要修改名字。
首先将node_modules中的文件夹和 JS 文件名字中的”-“替换成”_”。
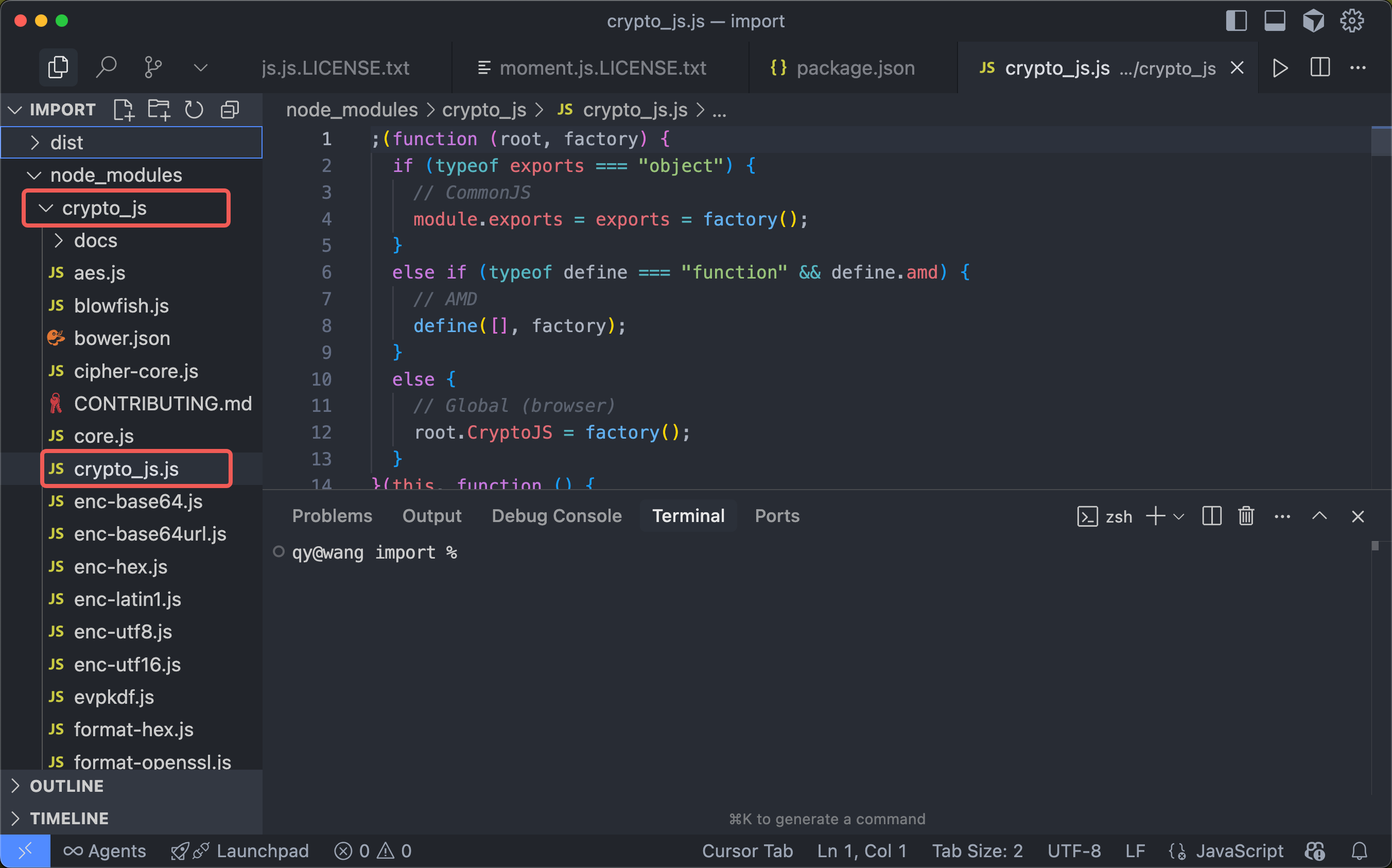
再修改 webpack.config.js 配置如下:
module.exports = {
entry: './node_modules/crypto_js/crypto_js.js',
output: {
filename: 'crypto_js.js',
library: 'crypto_js',
libraryTarget: 'var'
}
}打包
接下来,使用以下指令开始打包
npx webpack-cli -c webpack.config.js 打包完成后,会在当前目录下生成一个dist文件夹,里面包含一个${moduleName}.js文件。
复制到代码块中
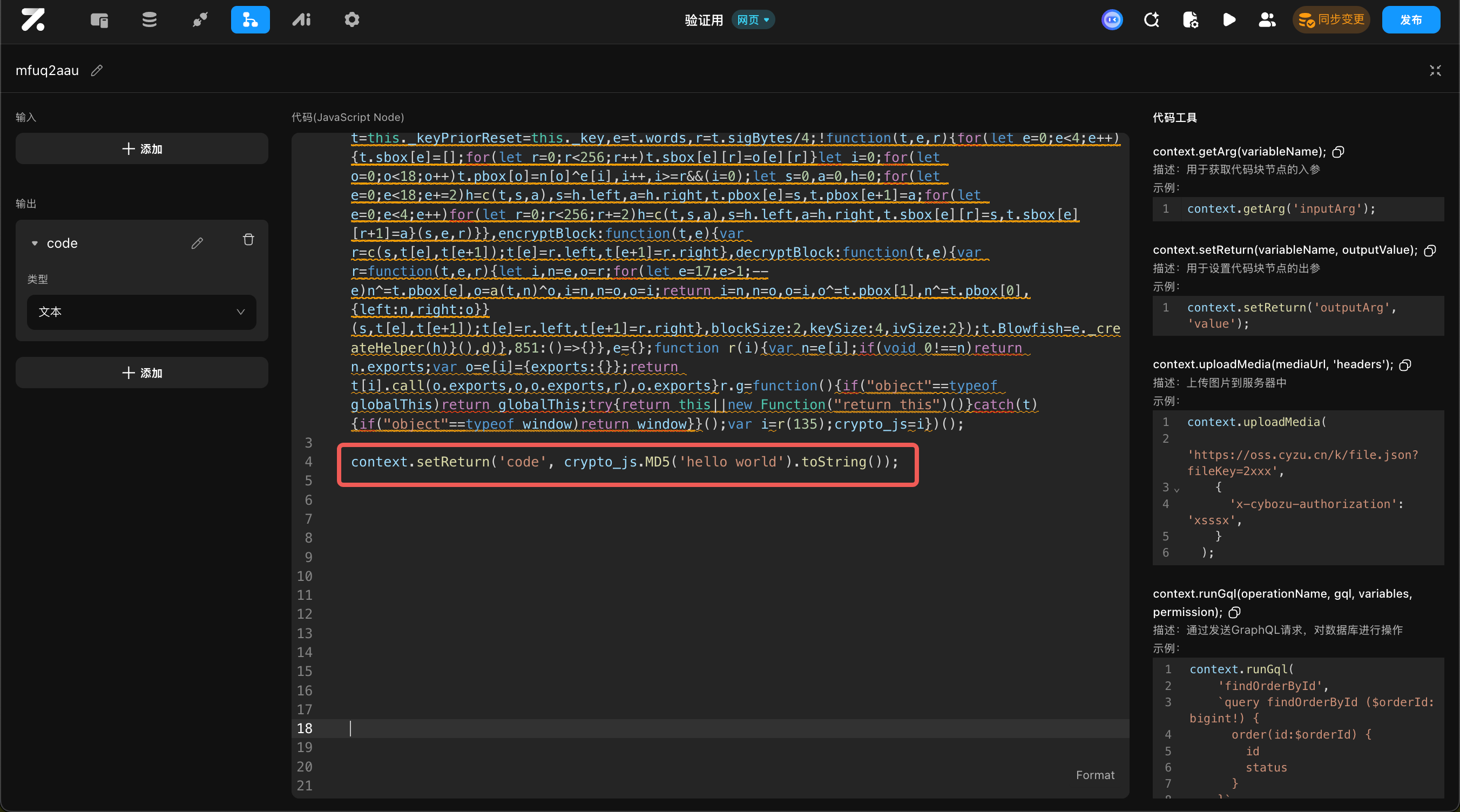
将文件中的代码全部复制到代码块中,就完成了导入第三方库的操作。
使用第三方库
接下来就可以使用第三方库中的方法了。
在打包的配置文件中,library 的值就是第三方库的名称,在本例中是crypto_js。建议先在 vsCode 等编辑器中,利用智能提示先查看在这个库中有哪些方法。
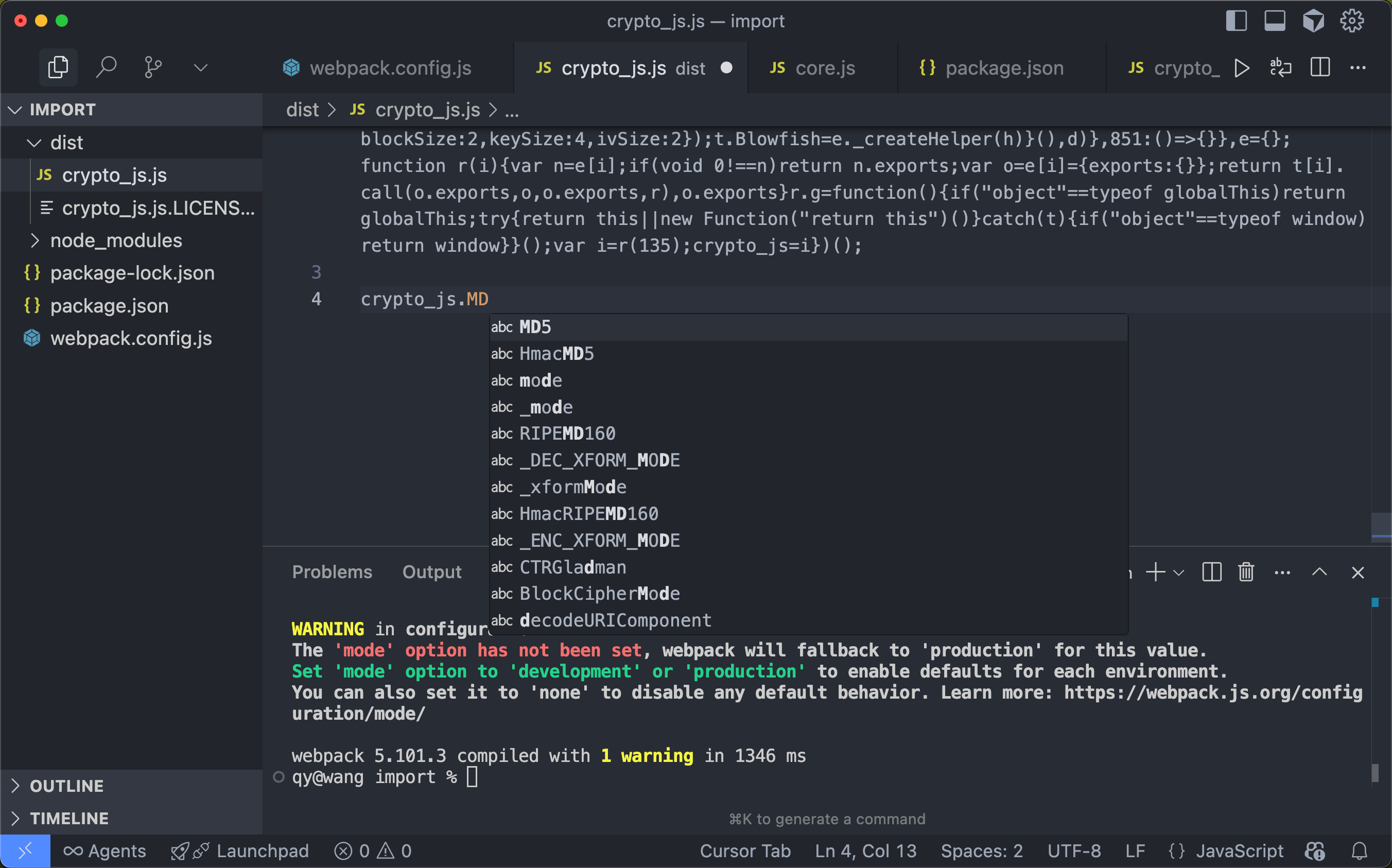
然后再在代码块中使用。