Zion 数据库配置
Zion 提供功能强大的关系型数据库,基于 PostgreSQL 构建,具备高性能、高灵活性和企业级功能特性。本文将从以下四个方面进行介绍:
- 数据模型:管理数据表、字段类型与表间关联。
- 约束设置:为字段设置唯一性约束,确保数据准确性。
- 向量化存储:开启 AI 功能,实现高效的向量存储与检索。
- 权限配置:配置数据的访问规则,实现精细化的数据安全管控。
数据模型
数据模型是数据库的基石,它定义了数据的整体样貌。Zion 支持便捷的表管理。

添加表
每个项目都会包含多张系统表,例如:帐户表、支付表等。系统表不可删除,除帐户表外的系统表不可修改。
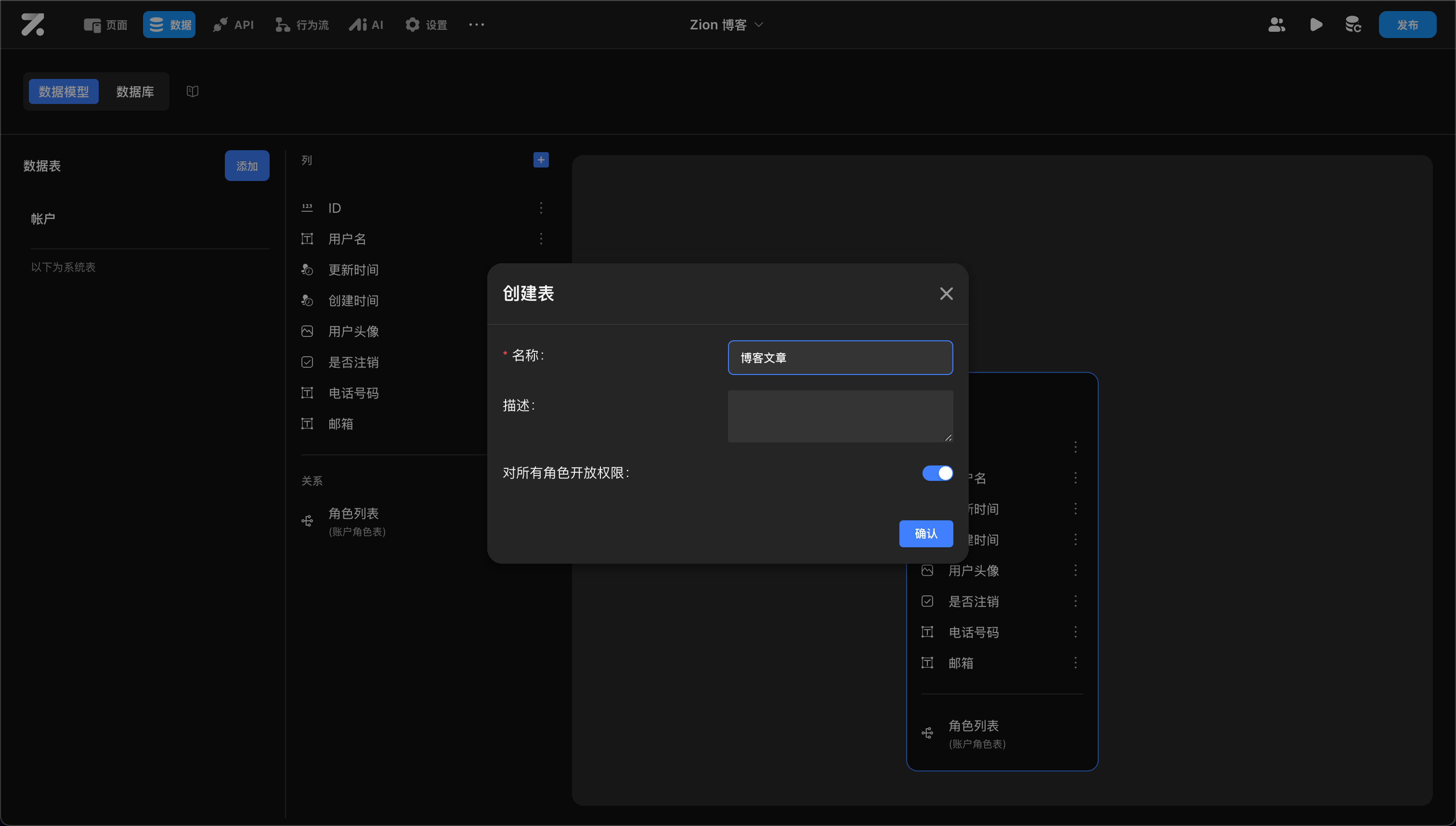
添加表时需要设置以下属性:
- 名称:禁止使用“log”、“column”、“index”等保留字
- 描述:表的说明(非必填)
- 对所有角色开放权限:是否将表的增删改查权限开放给所有角色
添加字段
每张表默认包含 id、创建时间、更新时间三列(系统自动维护,不可修改/删除)。
添加字段时需设置:
- 名称:避免使用“column”等保留字
- 类型:支持以下类型:文本、整数、无限精度小数、日期时间(带时区)、日期、时间(带时区)、图片、视频、文件、经纬度、JSONB
- 必须:是否为必填项
- 唯一:是否唯一(如用户名)
- 对所有角色开放权限:是否将字段的增删改查权限开放给所有角色
Zion 数据库采用无限精度小数(Decimal)以确保数值的精确存储。然而,如果使用了 API、Webhook 中的双精度浮点数类型,或使用代码块处理数据(无论是整数还是小数,Javascript 统一使用双精度浮点数表示)时,可能会造成精度丢失。
例如,数据库里存了两个完全精确的数字:0.1和0.2。
当代码块读取这两个数字时,会把它转换成近似的浮点数来处理。
此时,用这两个近似的浮点数相加,计算结果会产生一个微小的误差,得到 0.30000000000000004。
如果将它们相加的结果保存至数据库,会保存精确的 0.30000000000000004。
例如,在博客表中添加标题、内容、封面、发布时间
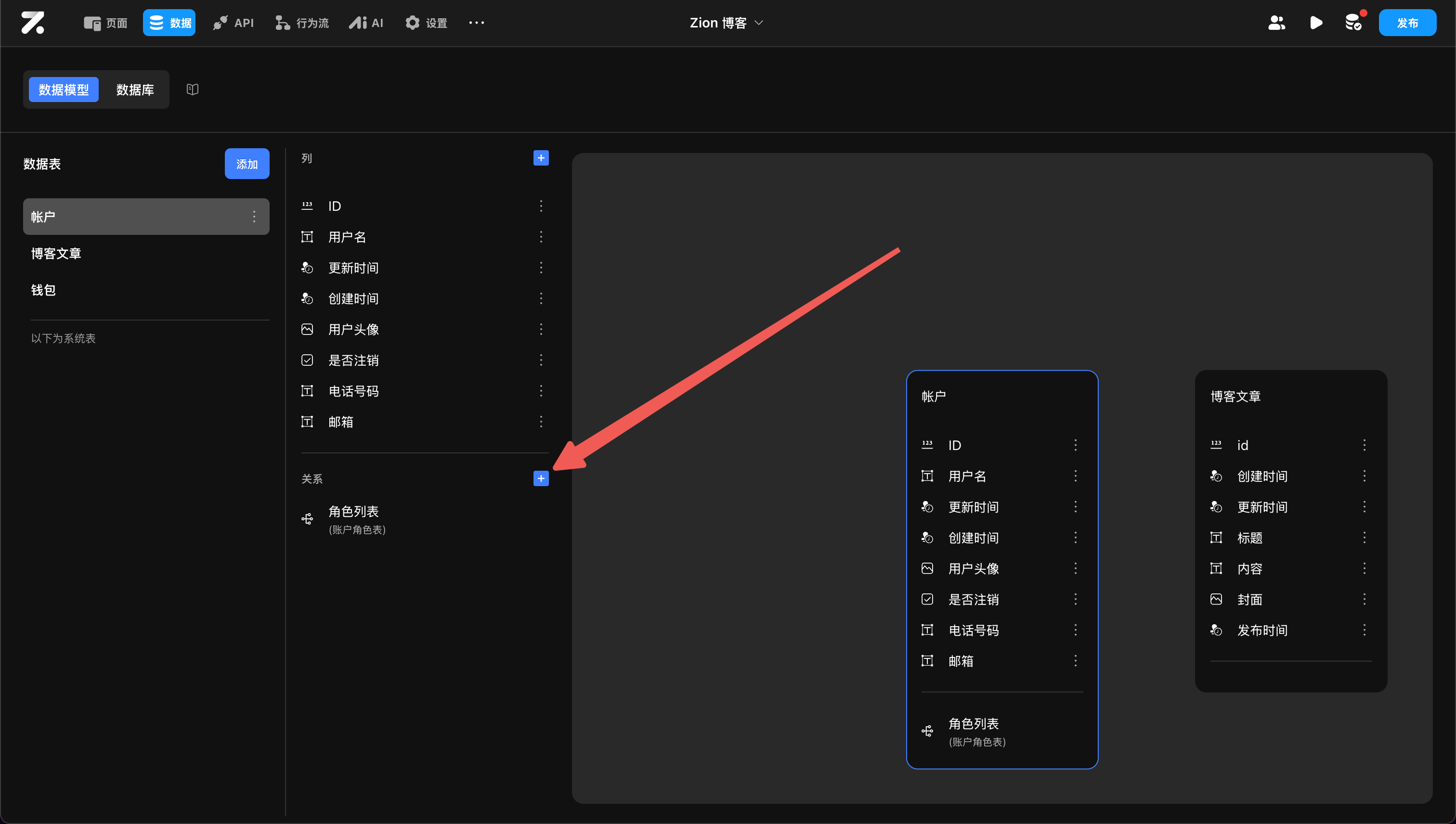
添加表关联
表间可通过 id 建立关联。例如,账户表与博客文章表需要建立关联,用于表示博客文章的作者。建立关联后,博客文章表会新增一列来保存账户表的 id。

在建关联时需明确:
-
目标表:需要关联的表
-
关系类型:一对一、一对多
-
关系名称(目标表/当前表):在对应表中的字段名称
-
对所有角色开放权限:权限管理,打开后所有角色都有该字段的编辑权限
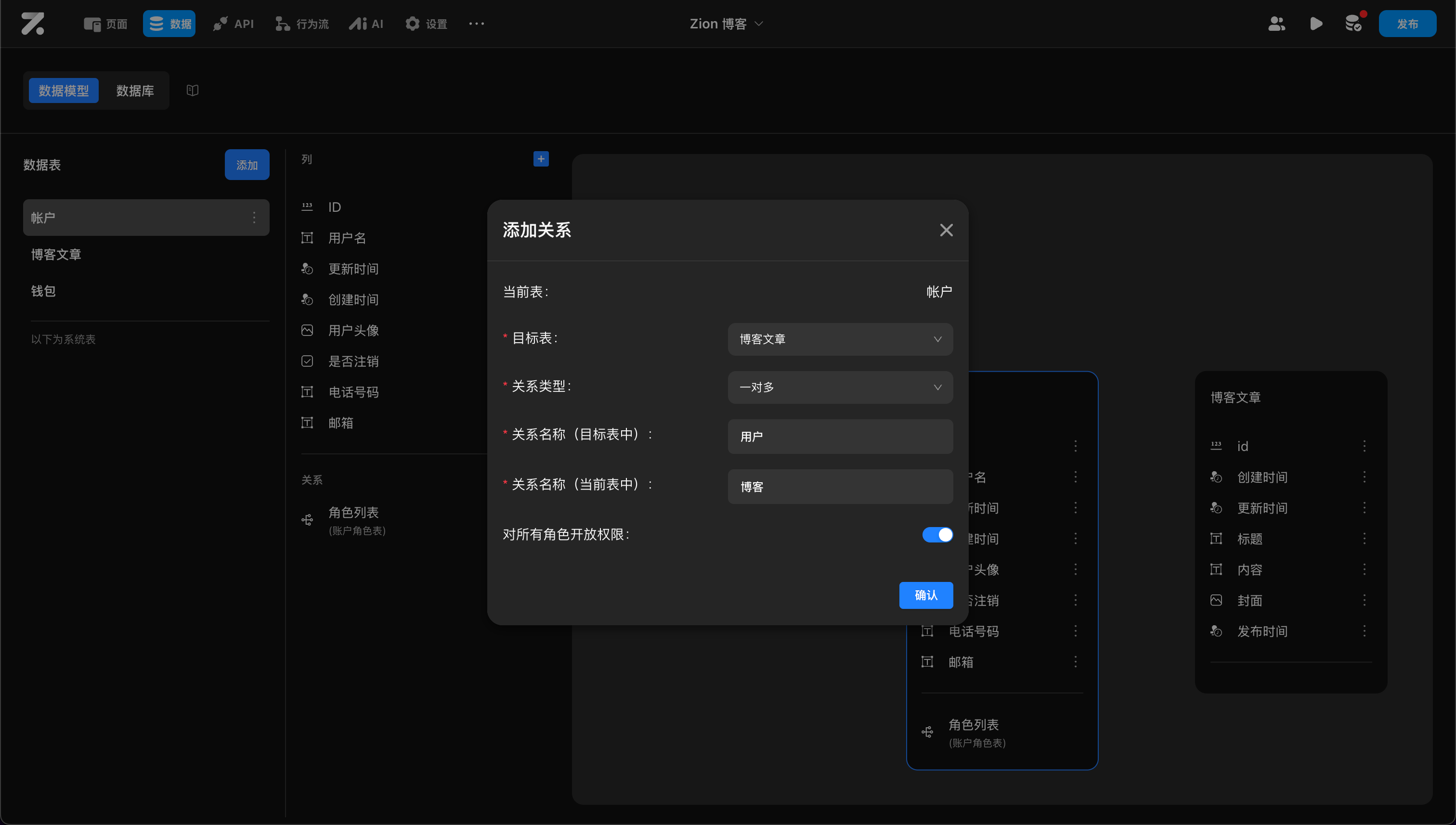
用前面的例子来说明,帐户表需要和博客表建关联:
- 目标表为博客表
- 由于一个用户可以有多篇博客,所以关系类型为一对多
- 在帐户表中关系名称为“博客”,在博客表中关系名称为“用户”。(在实际使用中,系统会给关联表自动添加表名后缀,如“用户_帐户”,这里为了方便省略了后缀。)
关联关系是数据模型重要且难懂的部分,接下来仔细说明。关联类型分为以下三种:
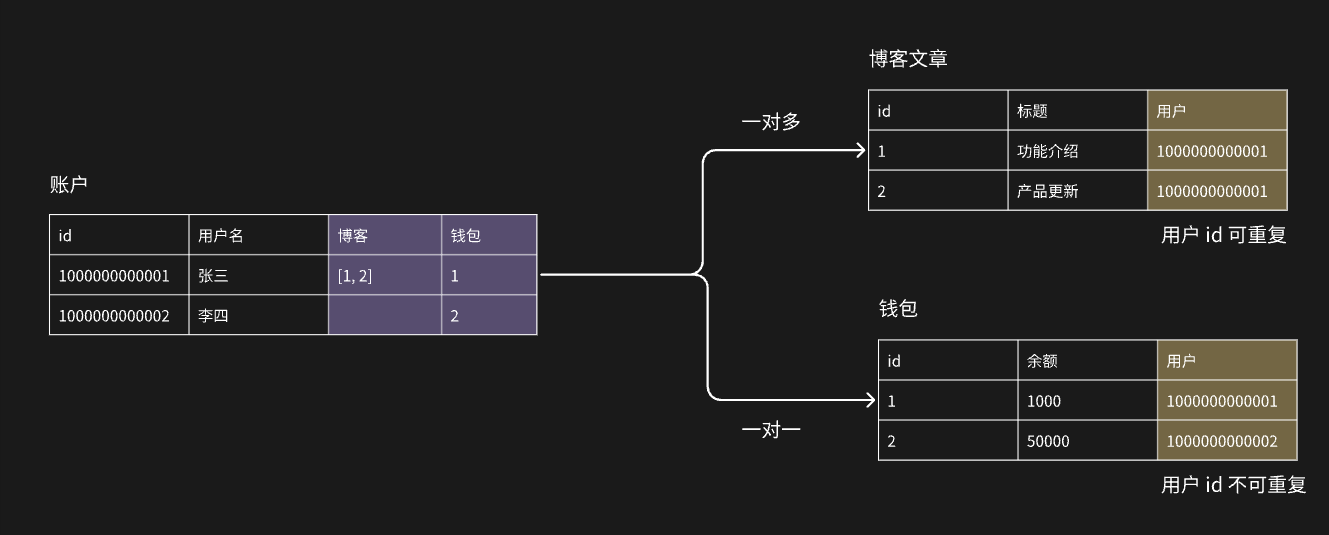
-
一对一:指 A 表中的一行数据可以与 B 表中 1 行数据关联。例如一个用户仅有一个钱包
-
一对多:指 A 表中的一行数据可以与 B 表中多行数据关联。例如一个用户可拥有多篇博客
-
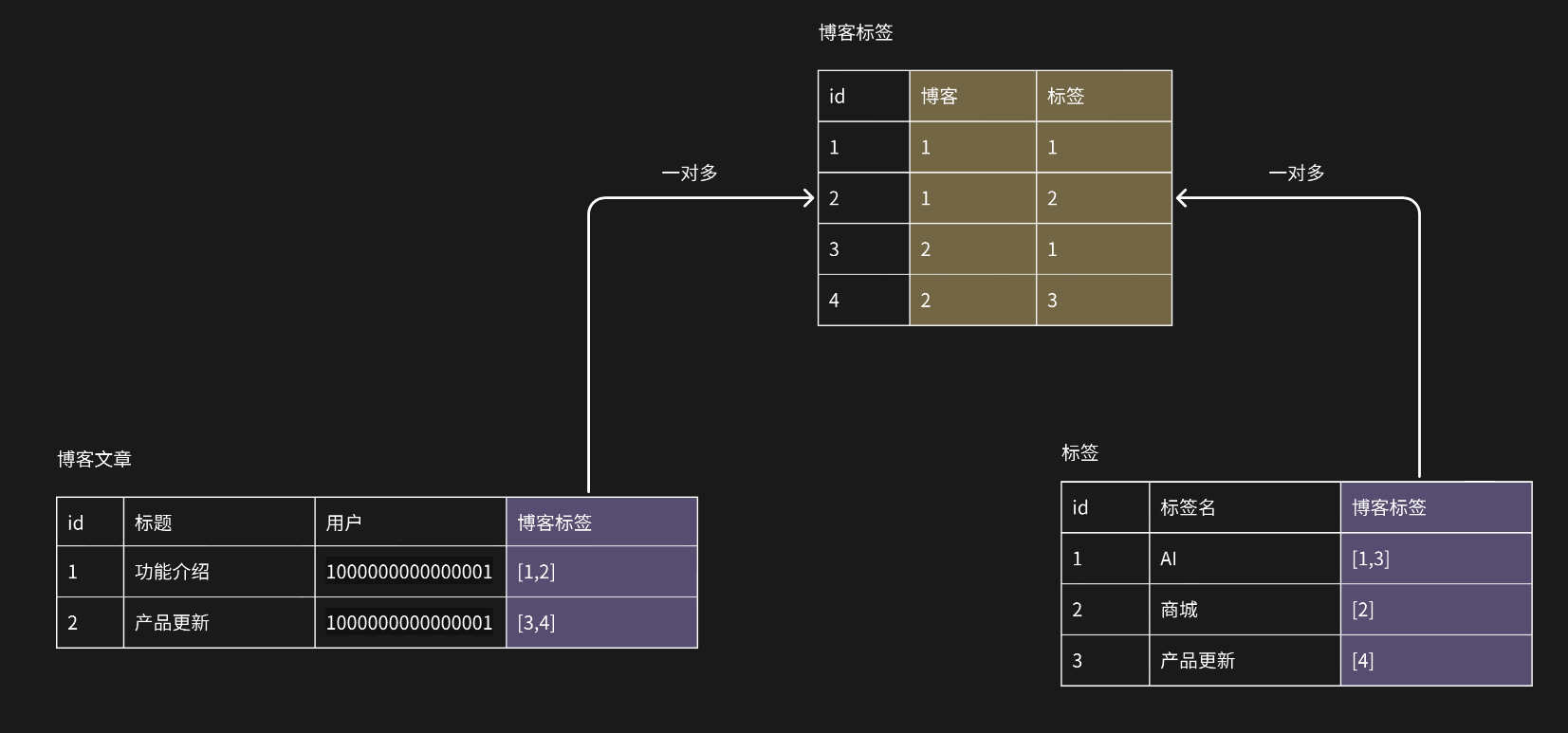
多对多:指 A 表中的一行数据可以与 B 表中多行数据关联,同时 B 表中的一行数据也可以与 A 表中多行数据关联。例:一个博客可以有多个标签,同时一个标签可以有多个博客。
系统提供了一对一和一对多两种关联类型,可以方便地创建出来。
若需要建立多对多关联,需要执行以下步骤:
- 创建一张中间表,用于保存 A 表和 B 表的对应关系。
- A 表、B 表都要向中间表建一对多的关联。
例如现在有两张表:博客表和标签表,要给他们建立多对多关系,则需要:
- 先创建中间表“博客标签”
- 博客表和标签表都向中间表建立一对多的关联。此时中间表中新增了两列分别用于保存博客 id 和 标签 id。它的每一行数据就是一个对应关系,这样就实现了多对多关联。
同步后端
同步后端,使数据模型变更在线上生效。
如果你的应用已经上线运营,对数据模型的变更可能导致线上请求失效,请谨慎操作。
约束设置
支持“唯一约束”的设置,可指定某些字段或字段组合不可重复。
打开约束设置
在表的修改菜单中,点击“编辑约束”选项,即可打开约束设置。
添加约束
每张表都会有一个默认的 id 约束,用于保证 id 的唯一性。
添加约束时需确定:
- 约束名称:不可重复,禁止中文和大写字母
- 列集合:表示哪些列需要被约束,可以选择单列或多列。如果是单列,表示该列的值不能重复。如果是多列,表示这些列的组合不能重复。
- 存储限制:约束列的单行数据总长度不得超过 8191 字节 (Bytes)。在 UTF-8 编码下,这约等于 2730 个汉字(每个汉字占用 3 字节)。
例如为了实现每个用户不能有标题重复的博客,可以设置约束:
标题和用户_帐户的组合不能重复。
同步后端
同步后端后,约束设置在线上生效。需要注意:
- 如果已有的数据违反了唯一约束,将导致同步后端失败
- 一旦成功同步后端,约束将不可编辑
- 如果想删除约束,需要将该约束列集合中的某一个列删除
向量化存储与排序
目前仅支持文本类型向量化。
向量化存储 指将文本字段通过大模型转为向量,实现基于相似度的排序。
例如,可以将博客内容进行向量化,实现文章推荐:
- 用户输入感兴趣内容
- 计算输入与文章内容的向量距离,按距离排序
- 取最相关的若干篇文章
打开向量化存储
在文本字段的修改菜单中,点击“选择模型开启向量存储”选项,并选择相应的词嵌入大模型。系统提供了 Ada 大模型,用户也可以在 AI 配置中自主添加其他大模型。
使用向量化排序
获取数据时,使用开启了向量化存储的字段进行排序,即使用向量距离进行排序。目前支持两种距离算法:
- EUCLIDEAN(欧氏距离):适合绝对差异场景,如物流路径优化
- COSINE(余弦距离):适合方向相似性场景,如文本推荐
权限管理
数据是项目核心资产。Zion 结合 RBAC(基于角色)与 ABAC(基于属性)权限系统,保障数据安全并实现灵活控制。详见权限管理.
数据的管理和使用
数据库配置完成后: