公式与条件数据
公式大全
类型转换
| 名称 | 描述 | 示例输入 | 示例输出 |
|---|---|---|---|
| TO_TEXT | 将整数、小数、布尔值或 JSON 转为文本 | -3.1415926 | "-3.1415926" |
| TEXT_TO_INTEGER | 将文本转为整数 | "-3.1415926" | -3 |
| TO_DECIMAL | 文本转为小数 | "-3.1415926" | -3.1415926 |
| TEXT_TO_DATETIME | 文本转为日期时间 | "2025-02-21 14:36" | 2025-02-21T14:36:00.000+08:00 |
| COMBINE_DATE_AND_TIME | 合并日期和时间为日期时间 | 日期:2024-01-08时间: 13:38:00.000+08:00 | 2024-01-08T13:38:00.000+08:00 |
| EXTRACT_DATE_OR_TIME | 提取日期时间中的日期或时间 | 2024-01-08 13:38:00.000+08:00 | 2024-01-08 |
文本处理
| 名称 | 描述 | 示例输入 | 示例输出 |
|---|---|---|---|
| TEXT_LEN | 返回文本长度 | "Hello World!" | 12 |
| REPLACE_PART | 替换指定位置的文本 | 文本:"Hello World!"起始位置: 1替换字符数: 4新文本: "ola" | "Hola World!" |
| REPLACE_TEXT | 替换指定文本 | 文本:"Hello World!"旧文本: "o"新文本: ""替换次数: 1 | "Hell World" |
| FIND | 返回指定文本首次出现的位置 | 文本:"Hello World!"要定位的文本: "o" | 4 |
| CONTAINS | 判断是否存在指定文本 | 文本:"Hello World!"要查找的文本: "ello" | true |
| SUB_TEXT | 截取一段子文本 | 文本:"Hello World!"开始位置: 0结束位置: 5 | "Hello" |
| LEFT | 从文本头部返回指定字符数 | 文本:"Hello World!"字符数: 5 | "Hello" |
| RIGHT | 从文本尾部返回指定字符数 | 文本:"Hello World!"字符数: 5 | "World" |
| LOWER | 转为小写 | "Hello World!" | "hello world!" |
| UPPER | 转为大写 | "Hello World!" | "HELLO WORLD!" |
| RANDOM_TEXT | 生成随机文本 | 最小长度:5最大长度: 10小写: true大写: true数字: true | "seXr3aoRD" |
| SPLIT | 按指定字符分割文本为数组 | 文本:"2024/01/08"分隔符: "/" | ["2024", "01", "08"] |
| ENCODE_URL | 将文本字符串转换成符合 URL 标准的格式 | 文本:"https://docs.functorz.com/starts/#入门教学视频" | "https%3A%2F%2Fdocs.functorz.com%2Fstarts%2F%23%E5%85%A5%E9%97%A8%E6%95%99%E5%AD%A6%E8%A7%86%E9%A2%91" |
| DECODE_URL | 解码一个由ENCODE_URL 函数编码过的 URL | 文本:"%E5%87%BD%E5%AD%90%E7%A7%91%E6%8A%80" | "https://docs.functorz.com/starts/#入门教学视频" |
| UUID | 随机生成字符串类型的唯一标识符 | 无 | "550e8400-e29b-41d4-a716-446655440000" |
| TEXT_REPEAT | 将文本重复指定的次数 | 文本:"对"重复次数: 3 | "对对对" |
| TRIM | 移除文本开头和结尾的空格 | " dadada " | "dadada" |
| REGEX_EXTRACT | 提取第一段与正则匹配的文本 | 文本:"电话号码是 13940983244"正则: \d{11} | "13940983244" |
| REGEX_EXTRACT_ALL | 返回所有与正则匹配的文本 | 文本:"电话:13940983244 和 13234322452"正则: \d{11} | ["13940983244","13234322452"] |
| REGEX_MATCH | 判断文本是否包含与正则匹配的内容 | 文本:"13812345678"正则: ^\d{11}$ | true |
| REGEX_REPLACE | 替换文本中与正则匹配的部分 | 源文本:"电话号码是13812345678"正则: \d{11}替换: "***********" | "电话号码是 ***********" |
数学运算
| 名称 | 描述 | 示例输入 | 示例输出 |
|---|---|---|---|
| + | 数字加法 | 数字1:5数字2: 10 | 15 |
| - | 数字减法 | 数字1:5数字2: 10 | -5 |
| * | 数字乘法 | 数字1:5数字2: 10 | 50 |
| / | 数字除法 | 数字1:5数字2: 10 | 0.5 |
| % | 返回除后所得的余数,符号与被除数一致 | 被除数:-5除数: 10 | -5 |
| MIN | 返回最小值 | 数字1:5数字2: 10 | 5 |
| MAX | 返回最大值 | 数字1:5数字2: 10 | 10 |
| ROUND_UP | 返回向上最接近的整数 | 数字:3.5 | 4 |
| ROUND_DOWN | 返回向下最接近的整数 | 数字:-3.5 | -4 |
| INT | 取整 | 数字:-3.5 | -3 |
| ABS | 返回绝对值 | 数字:-3.5 | 3.5 |
| RANDOM_NUMBER | 返回指定数字之间的随机整数 | 最小值:1最大值: 10 | 6 |
| POWER | 幂运算 | 底数:2指数: 3 | 8 |
| FORMAT_DECIMAL | 小数格式化 | 小数:3.1415926精确到几位小数: 2舍入模式: HALF_EVEN清除末尾的所有零: true | 3.14 |
| LOG | 根据指定底数返回数字的对数 | 真数:8底数: 2 | 3 |
数组处理
| 名称 | 描述 | 示例输入 | 示例输出 |
|---|---|---|---|
| GET_ITEM | 从数组中获取一项,索引从0开始 | 数组:["2024", "01", "08"]索引: 1 | "01" |
| ARRAY_TO_ITEM | 从数组中获取一项(即将废弃,推荐使用GET_ITEM) | 数组:["2024", "01", "08"]索引: 1 | "01" |
| ARRAY_LENGTH | 获取数组的长度 | 数组:["2024", "01", "08"] | 3 |
| FIRST_ITEM | 返回数组的第一项 | 数组:["2024", "01", "08"] | "2024" |
| LAST_ITEM | 返回数组的最后一项 | 数组:["2024", "01", "08"] | "08" |
| RANDOM_ITEM | 返回数组的随机一项 | 数组:["2024", "01", "08"] | "01" |
| SLICE | 取出数组中的一段 | 数组:["2024", "01", "08"]开始位置: 1数量: 2 | ["01", "08"] |
| JOIN | 将文本类型的数组连接成字符串 | 数组:["2024", "01", "08"]连接符: "-" | "2024-01-08" |
| INDEX_OF | 返回指定项第一次出现的索引 | 数组:["2024", "01", "08"]指定项: "08" | 2 |
| SEQUENCE | 生成指定范围内的数字序列(包含头,不包含尾)。 | 起始数字:0结束数字: 10步长: 2 | [0,2,4,6,8] |
| COALESCE | 按从左到右的顺序,返回数组内第一个”非空”的项 | 数组:[null,1,3,2] | 1 |
| ARRAY_MAX | 返回数组中最大的值 | 数组:[1,2,3] | 3 |
| ARRAY_MIN | 返回数组中最小的值 | 数组:[1,2,3] | 1 |
| ARRAY_SUM | 返回数组中所有值的和 | 数组:[1,2,3] | 6 |
| ARRAY_AVERAGE | 返回数组内所有值的平均值 | 数组:[1,2,3] | 2 |
| ARRAY_CONCAT | 合并两个数组为1个数组 | 数组1:[1,2,3,4,5]数组2: [2,3,4] | [1,2,3,4,5,2,3,4] |
| UNIQUE | 去除数组当中重复项 | 数组:[1,2,5,4,5,2,3,4] | [1,2,5,4,3] |
| ARRAY_MAPPING | 对数组中的每个元素进行转换后,返回新数组。 | 原数组:[1,2,3,4]新数组项: 原数组项 * 10 | [10,20,30,40] |
| FILTER | 筛选出数组中符合条件的元素,返回新数组。 | 原数组:[1,2,3,4]条件: 原数组项 > 2 | [3,4] |
时间运算
| 名称 | 描述 | 示例输入 | 示例输出 |
|---|---|---|---|
| GET_DATE_TIME | 获取时间点 | 年:2024月: 1日: 8时: 13分: 14秒: 0 | 2024-01-08T13:14:00.000+08:00 |
| DELTA | 时间的加/减运算 | 时间:13:38:00.000+08:00运算类型: 加时: 1分: 12秒: 0 | 14:50:00.000+08:00 |
| DURATION | 计算两个时间点的间隔 | 开始:2019-12-01结束: 2024-01-08时间差转换为: 年 | 5 |
| EXTRACT | 获取时间中指定的部分。如果是获取星期几,输出0到6的整数,0 表示星期日 | 时间:13:38:00.000+08:00单位: 时 | 13 |
💡
- 日期:
2024-01-08代表年-月-日。 T是日期和时间的分隔符- 时间:
13:14:00.246046代表小时:分钟:秒.毫秒 - 时区:
+08:00代表这个时间是在UTC(协调世界时)基础上加8小时的时区,这通常对应于中国标准时间(CST)。
地理位置
| 名称 | 描述 | 示例输入 | 示例输出 |
|---|---|---|---|
| DISTANCE | 计算两个地理位置之间的距离。单位可选择为:米、千米、英里 | 位置1:[120.2934,30.3150]位置2: [120.2934,31.3150]单位:千米 | 866 |
| GET_VALUE_FROM_GEO_POINT | 从地理位置(经纬度)中获取经度或纬度 | 位置:[120.2934,30.3150]类型: 纬度 | 30.3150 |
JSON 处理方法
| 名称 | 描述 | 示例输入 | 示例输出 |
|---|---|---|---|
| JSON_EXTRACT_PATH | 从json中获取数据 | 输入Json:{"data": {"foo": "bar"}}路径: data.foo | "bar" |
条件数据
Zion 支持在组件和行为中使用条件数据,允许根据特定条件动态选择和展示数据。条件数据可以用于实现复杂的业务逻辑,例如根据用户角色、状态或其他条件展示不同的内容。
条件数据的配置方式如下:
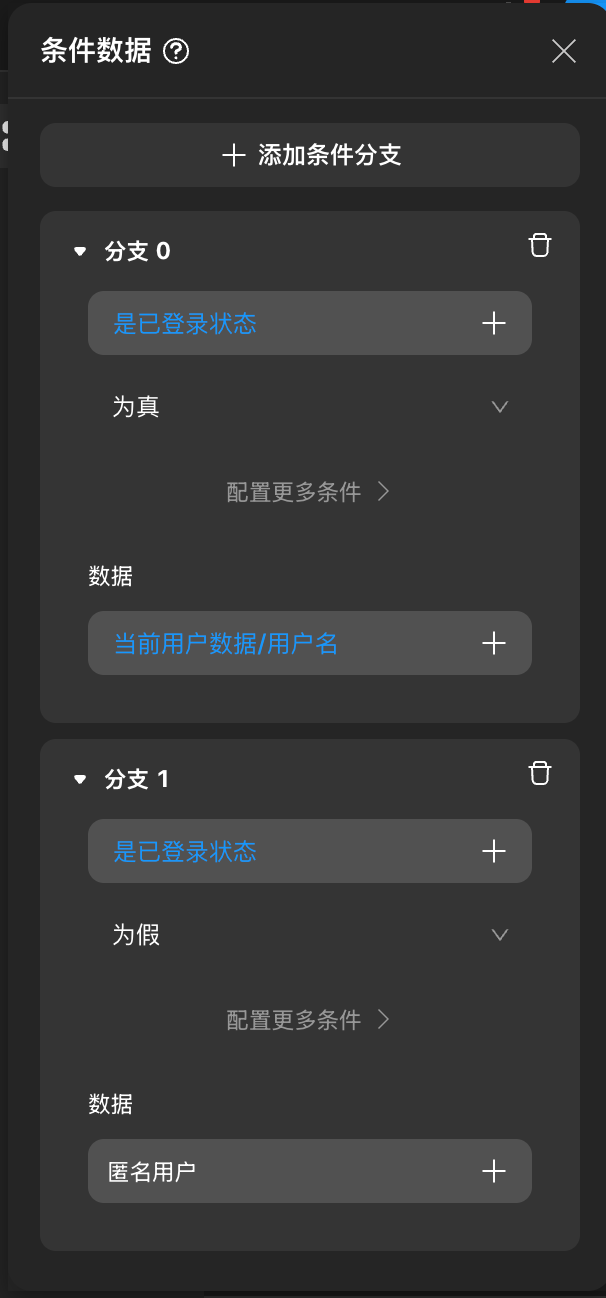
具体的例子如下:
{
"conditions": [
{
"case": "case1",
"condition": "user.isLoggedIn",
"data": {
"text": "欢迎回来,用户!"
}
},
{
"case": "case2",
"condition": "!user.isLoggedIn",
"data": {
"text": "请登录以继续。"
}
}
]
}在上述示例中,根据用户是否登录的状态,展示不同的文本内容。
Last updated on