数据模型配置
Zion 提供基于 PostgreSQL 的关系型数据库。本指南介绍如何添加数据表和字段、配置表间关联、唯一约束与数据权限。
需要进行语义搜索时,请参阅向量存储与排序。
数据模型配置
在顶部进入数据 → 数据库,可以查看和编辑项目的数据模型。

系统表与系统字段说明
除自定义数据表和字段外,项目还包含由平台功能维护的系统表与系统字段。
系统表
每个项目都包含由平台功能维护的系统表,例如账户、支付以及 AI 智能体运行数据相关的数据表。系统表不能删除;除账户表外,其他系统表也不能自行添加字段或修改表结构。
账户表支持添加自定义字段和配置关联,但账户记录必须通过注册、账户导入或对应的用户行为创建。登录密码等凭证保存在不对外开放的内部凭证表中;用户名、邮箱、手机号等可供业务使用的账户信息会同步到平台提供的账户字段。
其他系统表的数据由对应的平台功能写入。例如,支付功能会产生支付记录,AI 智能体运行时会产生会话和消息记录。不能在数据管理中手动为这些系统表添加一行数据。
系统字段
在任何数据表中(包括自定义表与系统表),Zion 都会在创建表时自动生成并维护三列默认的系统字段。这三个字段由系统直接托管,不可修改、删除或重命名。
| 系统字段名称 | 数据类型 | 作用与维护机制 |
|---|---|---|
id | 长整数 | 该行的主键,用于保证数据的唯一性。在每次新记录插入时自动递增。 |
创建时间 | 日期时间 | 该行记录首次插入数据库时的时间(带时区)。 |
更新时间 | 日期时间 | 该行记录最后一次被更新的时间(带时区)。数据发生实际修改时,由数据库自动更新。 |
数据库只保证 id 唯一性和递增性,但不保证连续性。以下情况均会引起 id 不连续:
- 删除了一行数据,新插入的数据的
id会跳过已删除的id - 执行事务性任务时,期间添加的数据的
id会被消耗,即使回滚也不会恢复 - 执行批量导入时,由于会给所有数据预生成
id,如果数据被跳过,或者导入失败导致回滚,都会让id不连续。
因此,不建议将 id 用作订单号、会员编号等面向用户且要求连续或稳定格式的业务编号。关联记录和查询具体数据时仍可使用 id。
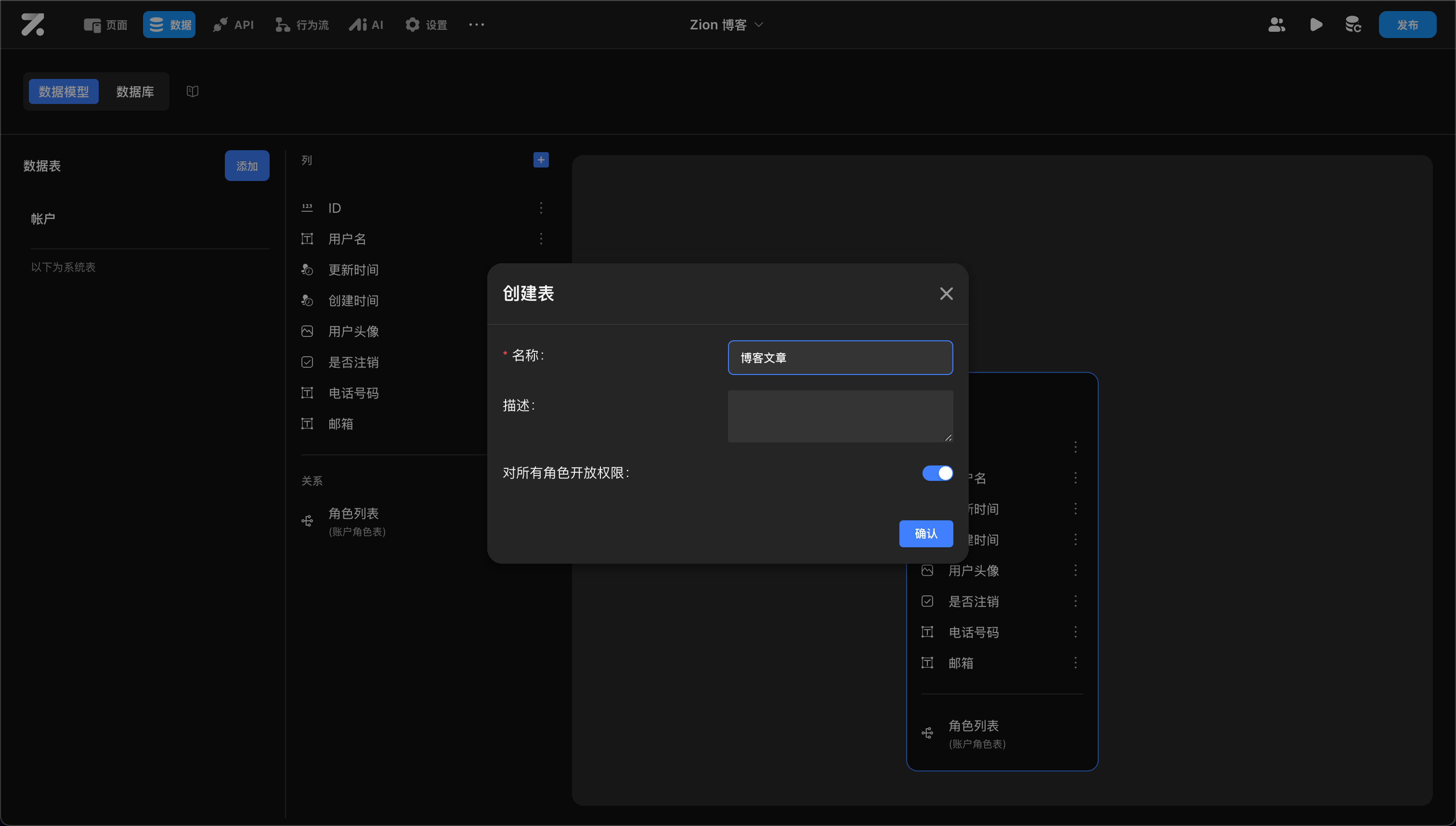
添加数据表
- 在数据库面板中点击“添加表”。
- 配置以下属性:
- 名称:必须使用小写字母和下划线命名(如
blog_article)。注意:禁止使用log、column、index等数据库底层保留字。 - 描述:说明表的业务用途。
- 对所有角色开放权限:是否允许所有角色对该表执行增删改查。正式使用前应按实际需求配置权限。
- 名称:必须使用小写字母和下划线命名(如
定义字段与数据类型
- 选中目标表,点击“添加字段”。
- 配置字段属性:
- 名称:使用小写字母和下划线(如
product_price)。 - 数据类型:根据数据的用途选择类型,完整说明请参阅数据类型。
- 必须(Not Null):配置是否为必填项。
- 唯一(Unique):配置该字段的内容是否在全表唯一(如手机号、工号)。
- 名称:使用小写字母和下划线(如
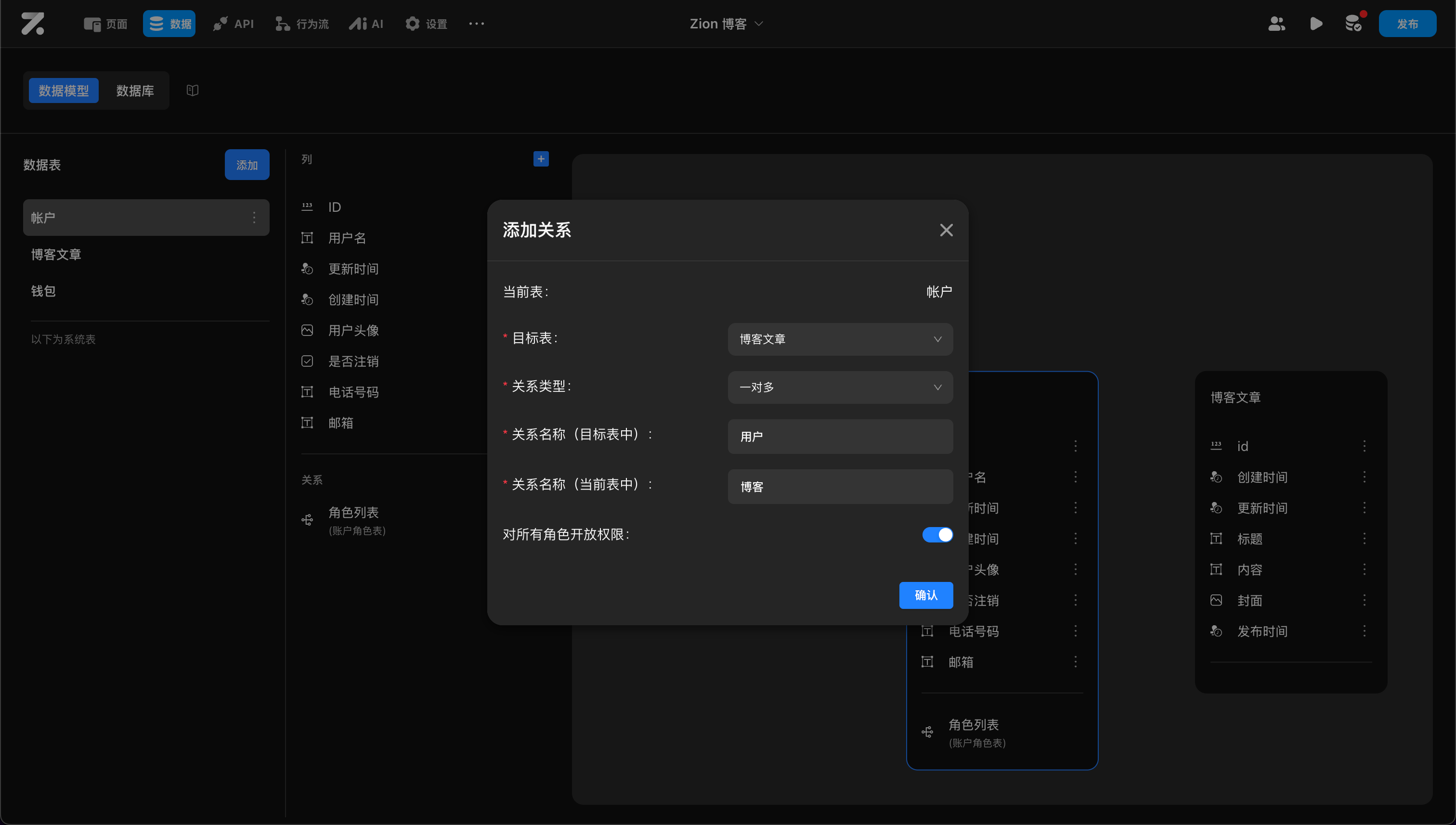
配置表间关联关系
通过 id 建立两张表之间的关联关系。例如,将“账户”表与“博客”表关联,用来标识每一篇博客的“作者(Account)”。建立关联后,系统会自动在博客表中生成一个外键关联字段。
- 在当前表中点击“添加关联”。
- 配置以下属性:
- 目标表:需要关联的目标数据表。
- 关系类型:选择 “一对一” 或 “一对多”。
- 关系名称:分别设置目标表和当前表中的关联字段别名(如在博客表中,关联字段别名称为
author_account)。
多对多关系的建模方式见关系型数据库思维。
同步变更
- 完成数据表、字段和关联关系配置后,点击项目详情页中的同步变更。
- 同步完成后,数据库结构变更才会生效,并且不能继续编辑本次待同步的配置。
唯一性约束设置
唯一约束用于防止单个字段或多个字段的组合出现重复值。
进入约束设置
在表的编辑菜单中,点击 “编辑约束”。
添加联合约束
除了单字段唯一外,还可以配置联合唯一约束。
- 名称:必须使用小写字母且不能重复,如
unique_user_blog_title。 - 列集合:选择参与唯一约束的字段。例如,将“标题”和“用户账户”组合后,同一用户不能创建两篇标题相同的文章,不同用户仍可使用相同标题。
同步后端
- 保存约束后,点击同步变更。
- 参与约束的字段内容合计不能超过 8,191 字节。UTF-8 字符占用的字节数不同,因此可输入的字符数不固定。
- 如果表中已经存在违反约束的重复数据,同步会失败。请先在数据管理中处理冲突数据,再次同步。
- 约束同步后不能直接编辑。需要调整时,先删除原约束并同步,再创建新约束。
权限管理
Zion 通过角色权限和数据权限控制不同用户可以读取或操作的数据。完成数据模型后,请继续配置权限。