AI 能力
概述
Zion 内置 AI 能力,开发者可创建高度定制化的 Agent,能自主定义 Prompt、RAG、工具调用等,结合 Zion 灵活的前端页面编排和强大的后端数据处理能力,可快速搭建商业级 AI 应用。
模型支持
可以使用 Zion 提供的大模型,也可以接入你自己的其他模型服务。
使用 Zion 提供的模型
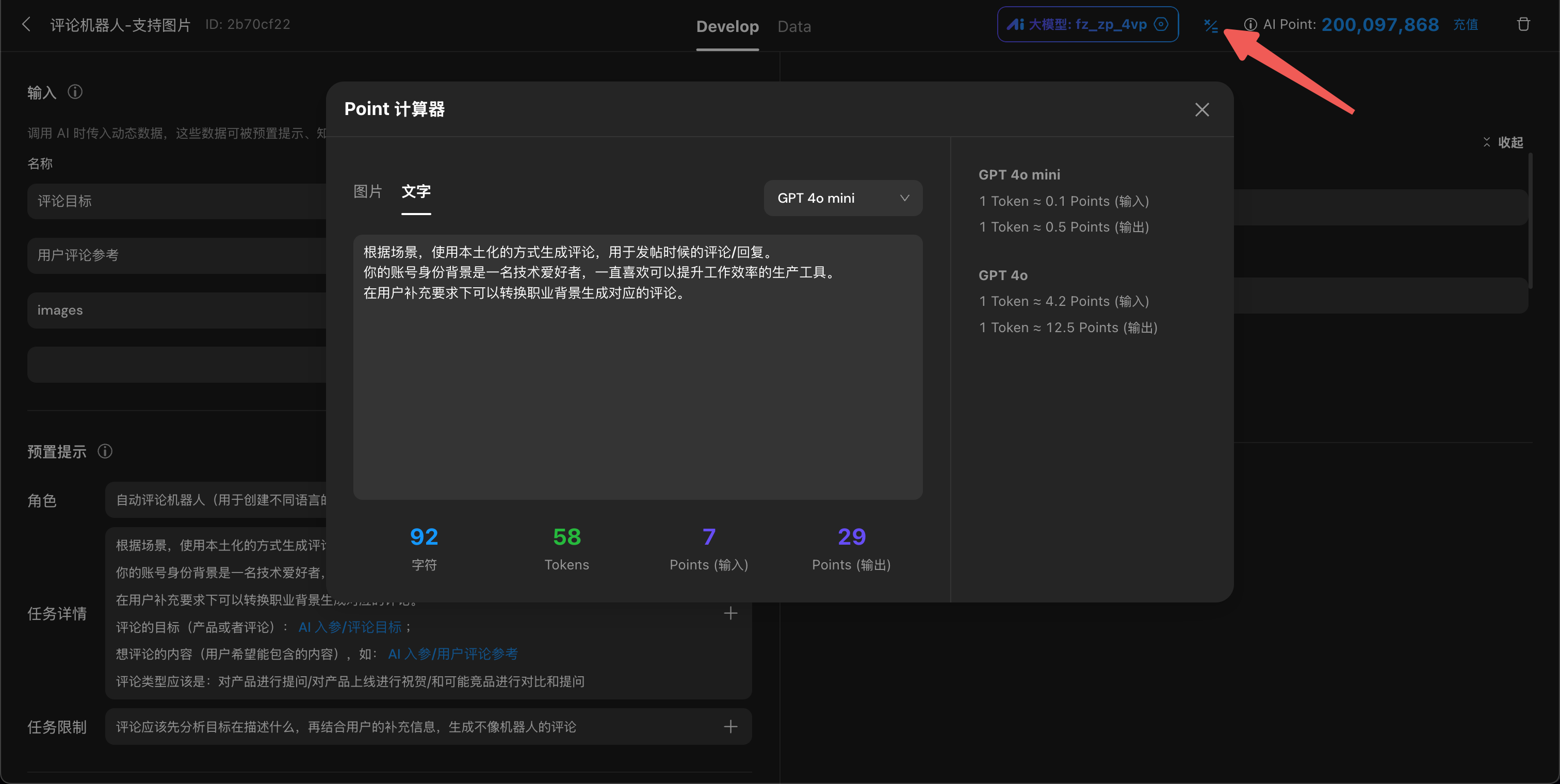
目前提供了 GPT 4o 和 GPT 4o mini 两个大模型。在使用它们时,会根据大模型消耗的 token 数量(区分输入输出),按比例扣除相应的 AI Point。
大部分情况下 GPT 4o 的 token 消耗量大于 GPT 4o mini。但是在处理图片时,mini 的 token 消耗量约为 4o 的33倍,换算成 Point 后它们的消耗量相当。
可以使用 Point 计算器,计算图片或文本的大概消耗量
AI Point 不足时将无法正常进行数据向量化、向量排序以及 Agent 调用。重新充值后,需要几分钟的时间生成之前没有生成的向量。
也可在项目详情中,查看 Points 的消耗记录
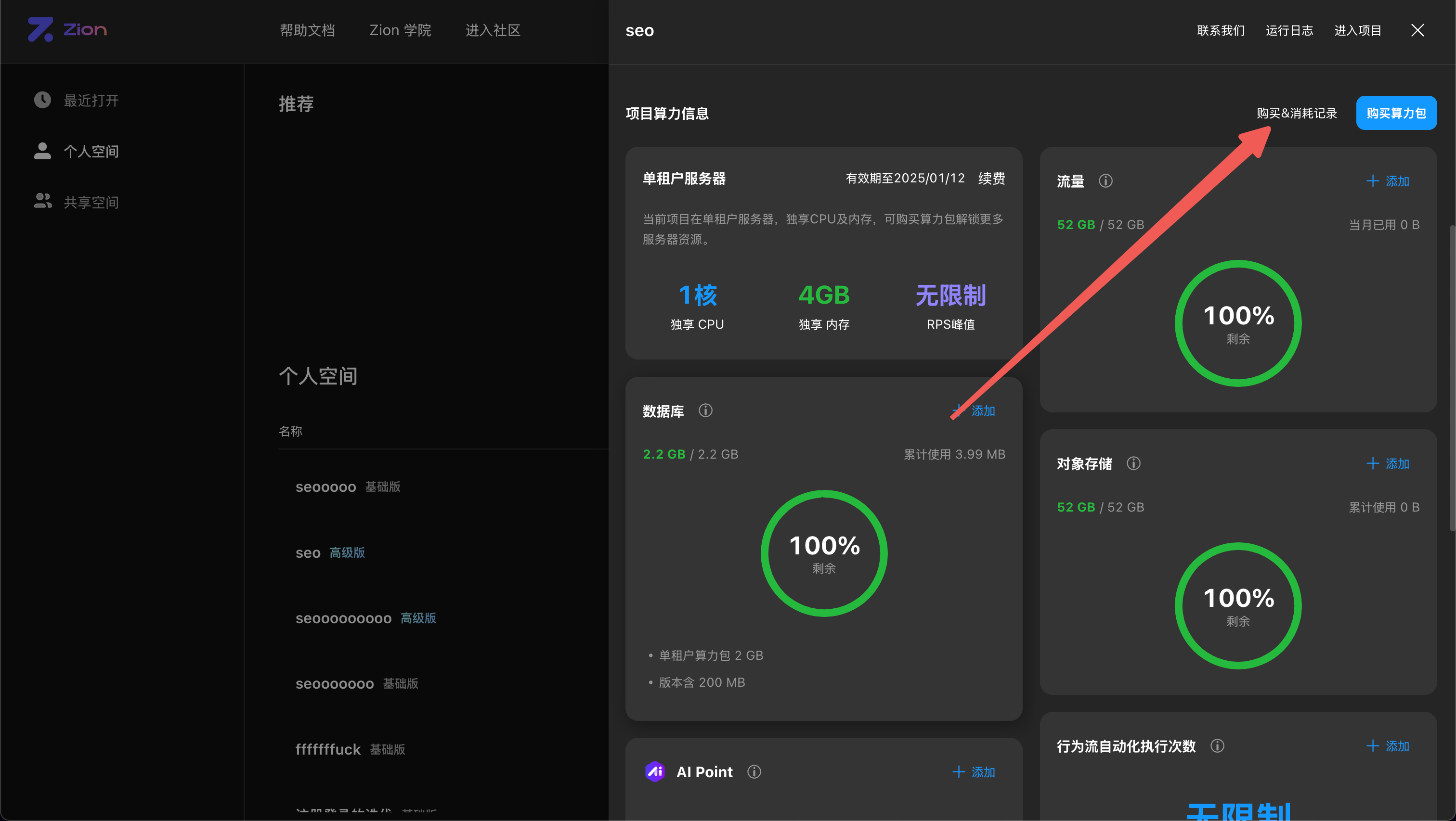
另外,每个月月初,系统会赠送 50, 000 AI Points,赠送的 Points 会在月末清零。
使用你自己的模型服务
如果你在其他平台开通了模型服务,或自己部署了大模型,可将其接入 Zion。此功能仅限付费项目使用。
目前支持的大模型有 DeepSeek 系列(包括一些蒸馏的大模型)和智谱系列大模型:
| 厂家 | 模型 | 支持的能力 |
|---|---|---|
| 深度求索 | DeepSeek-R1 | 思维过程、流式输出 |
| DeepSeek-V3 | 流式输出、结构化输出 | |
| DeepSeek-chat | 与 DeepSeek-V3 相同 | |
| DeepSeek-reasoner | 与 DeepSeek-R1 相同 | |
| 智谱 | glm-4-air | 流式输出、使用工具、结构化输出 |
| glm-4-flash | 流式输出、使用工具、结构化输出 | |
| glm-4-plus | 流式输出、使用工具、结构化输出 | |
| glm-4v | 流式输出、多模态、结构化输出 | |
| glm-4v-plus | 流式输出、多模态、结构化输出 | |
| glm-4-0520 | 流式输出、使用工具、结构化输出 |
在创建大模型时,需填写:
基本信息
名称:大模型配置名称,不可重复。
类型:确认大模型类型,推理或词嵌入。
平台:支持深度求索官方、智谱官方、阿里百炼、火山方舟、腾讯云、硅基流动、潞晨云、零氪云等平台,也支持你自部署的大模型(仅支持 DeepSeek)。
型号:大模型型号。
平台信息
若接入的是各大平台,则填写:
API Key:各平台的授权密钥,请自行前往平台获取。
接入点 ID:在接入火山方舟时特有的配置项,它真正控制了大模型的型号,此时前面第2点的”类型“配置无效。
自部署大模型服务信息
如果是你自行部署的大模型服务,则填写:
服务器 URL:自部署大模型服务的访问地址。
自定义鉴权方式的 Http Header 名称:鉴权方式的键名,例如"api-key: xxxxxxxxxxx"中的"api-key"
自定义鉴权方式的 Http Header 的值:鉴权方式的键值,例如"api-key: xxxxxxxxxxx"中的"xxxxxxxxxxx"
入参的模型值:模型的型号值,例如"DeepSeek-R1"
以上信息填写完后,点击“验证”。此时系统会尝试着用这些信息发送一次请求,如果请求成功,则验证通过。保存配置,并部署后端,该大模型就可以使用。

创建 Agent
通过编辑器左上角的“AI”进入,并创建 Agent。系统会自动在数据模型中创建“会话表”、“消息表”等,用来存储对话内容,具体可查看zai数据模型
设置模型参数
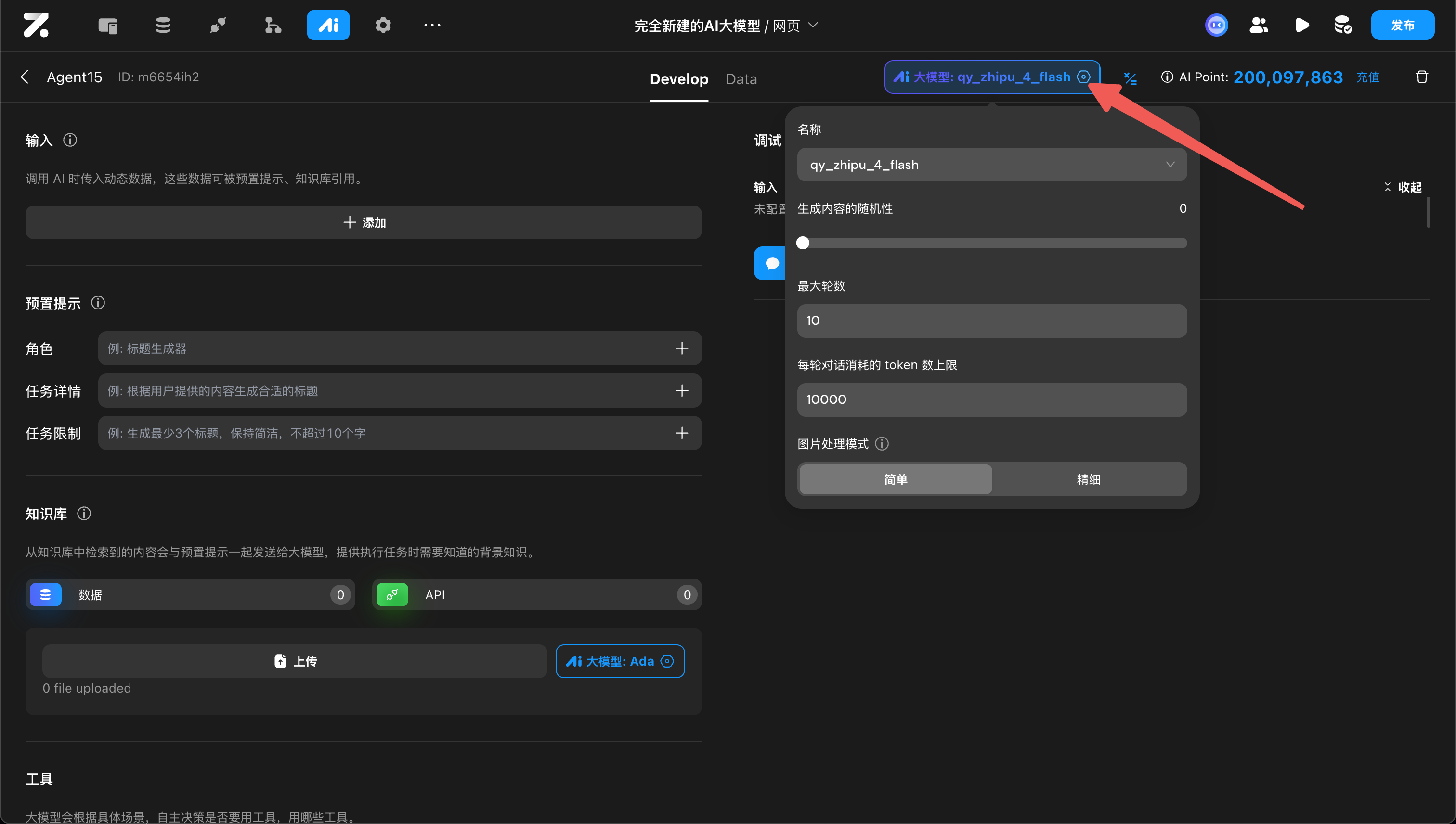
创建 Agent 后,接下来可以设置它的模型参数,包括:
大模型: 可以是 Zion 提供的,也可以是你自己的大模型服务
生成内容的随机性 (Temperature): 范围0到1,值越大随机性越大
最大轮数: 每个会话最多能进行多少轮对话,一问一答为一轮
每轮对话消耗的 token 数上限: 每轮最多消耗的 token 数,若超出上限,这轮对话会失败报错
图片处理模式: 大模型处理图片有简单和精细两种模式,精细模式的 token 消耗量大于简单模式
进行多轮对话时,每一轮新的对话都会带上历史消息,会导致每轮字数越来越多,消耗更多的 Point ,所以需要根据业务情况来设定每轮对话的 token 上线和最大轮数
设置输入
输入用于在调用 Agent 时,传入动态数据。输入可以被预置提示、知识库引用。
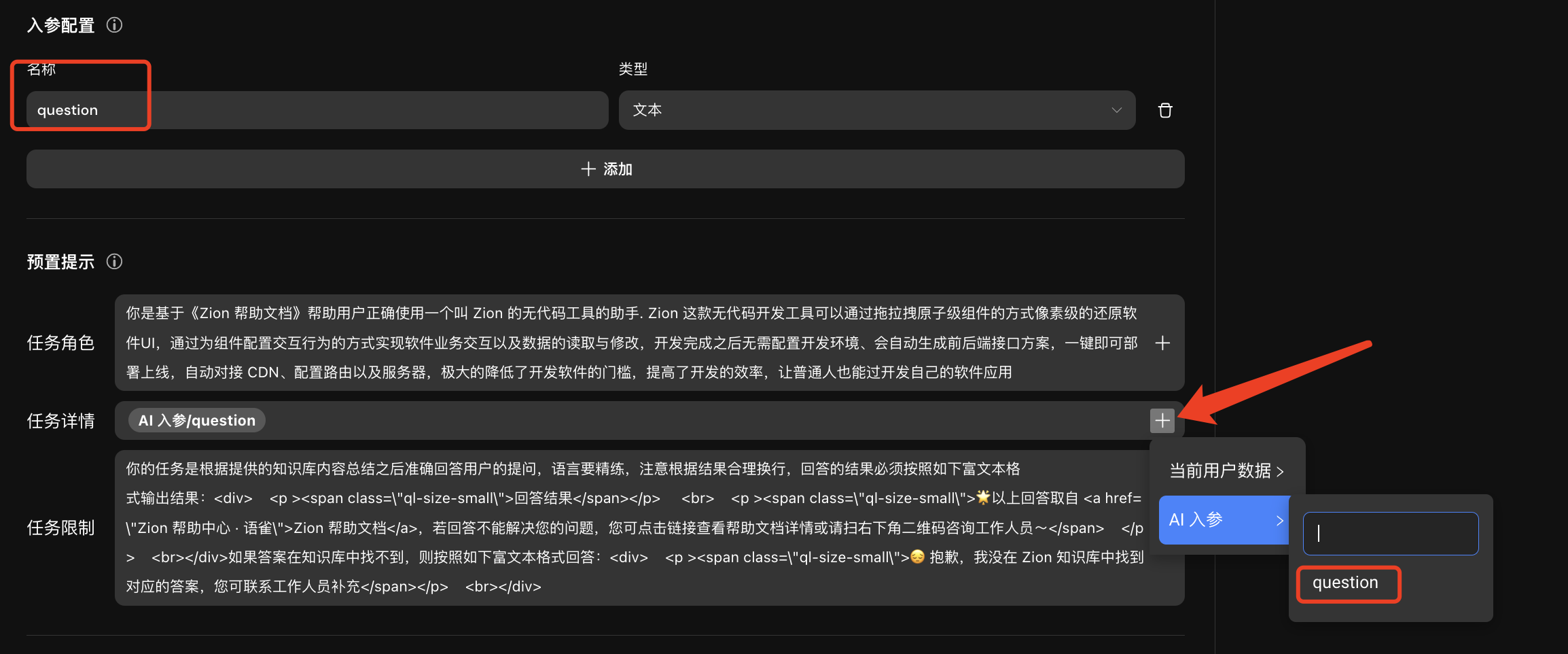
添加预置提示
即提示词,是发送给大模型的一段文本指令,告诉大模型要去完成什么任务或生成什么内容。在提示词中可以绑定当前用户数据和前文配置的入参来进行外部的数据输入。
任务角色(Role): 定义 Agent 是一个什么角色,让 Agent 更好的理解任务/问题,从而给出更好的结果,比如“帮助学生正确掌握英语语法的英语老师”、“保险公司的理赔专员”、”小红书母婴专栏作家“等
任务详情(Goals): 定义要去执行的任务是什么,比如是要让去回答问题、编写文案还是做信息提取,以及是否要结合其它一些上下文或者知识库来作为执行任务时候的参考
任务限制(Constraint): 执行任务时候的限制条件,比如要做什么、不要做什么、多少字数、要包括什么关键词、需要什么风格、需要精确到几位数,生成富文本等等

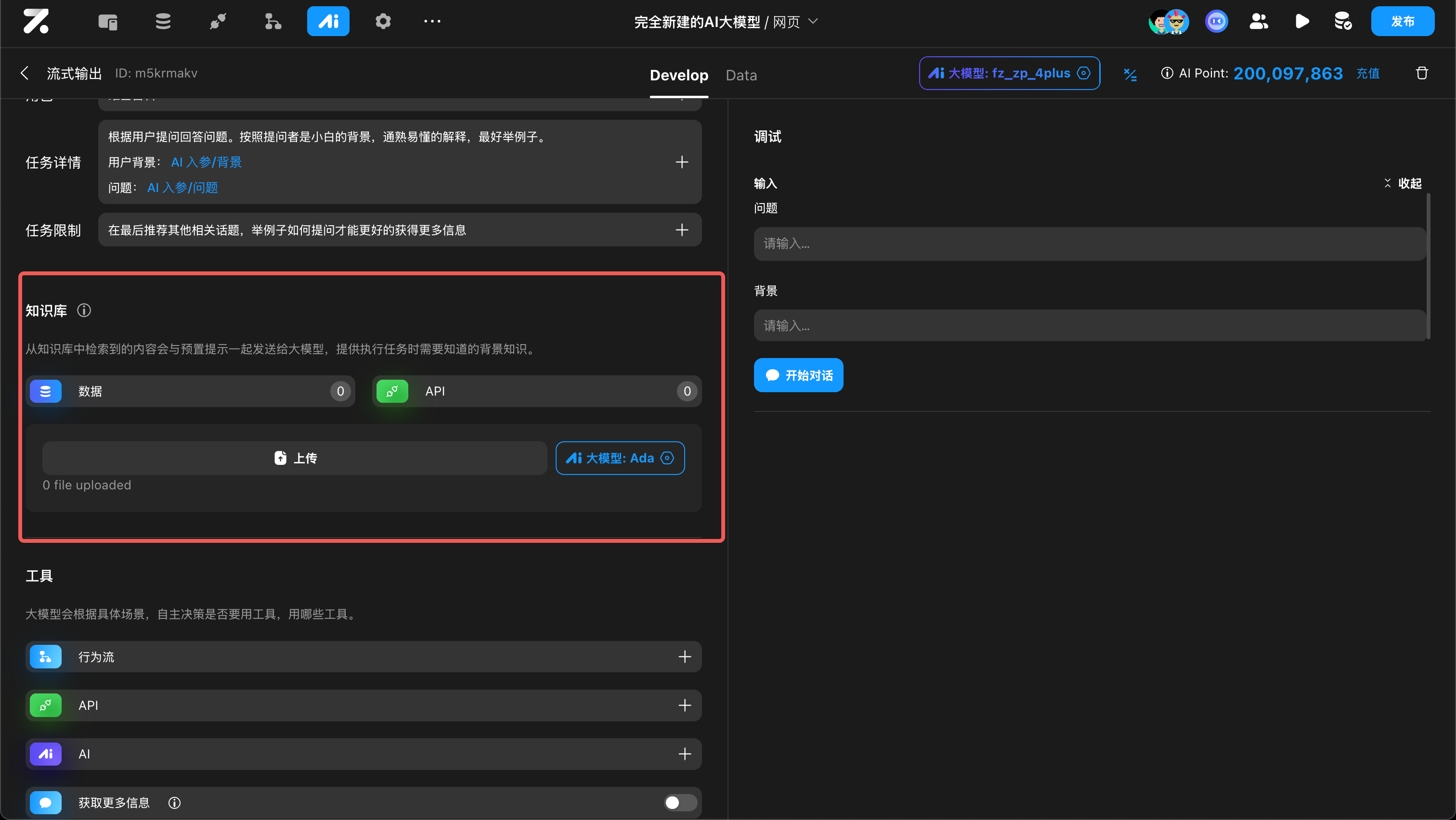
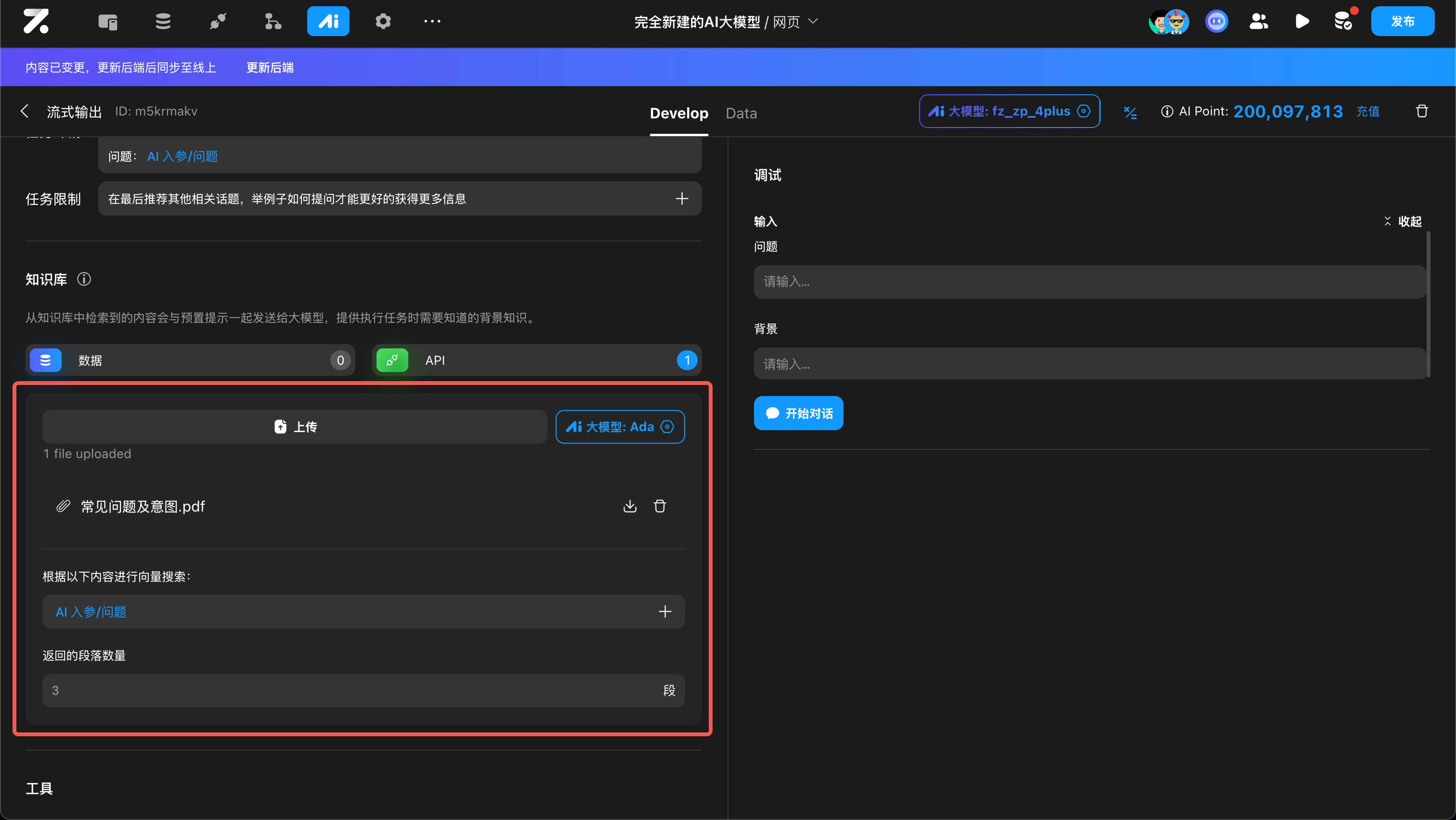
配置知识库
从知识库中检索到的结果会与预置提示一起发送给 Agent ,提供执行任务时需要知道的知识:
扩展知识领域:为大模型提供额外的领域专业知识,使其能够回答更广泛的问题。这有助于提高模型的通用性,使其在各种领域都表现出色。
提供实时信息: 可以包含最新的数据和信息,帮助大模型了解当前的事件和趋势。这对于涉及时事新闻、股票市场、天气预报等信息的任务特别有用。
更多作用:改善答案的准确性、提高语境理解、处理稀有领域问题、语言翻译和跨文化理解、弥补知识不足
例1: 我想做一个 Zion AI 开发小助手,用户可以向这个小助手提问关于 Zion 的开发使用相关问题,为了让 AI 能够准确回答用户问题,就需要给 AI 提供 Zion 的官方文档
例2:我想做一个公司内部财务报销小助手,公司内部同事在报销时可以预先提问 AI 助手,为了让 AI 能够精准回答同事的问题,就需要给 AI 提供公司财务报销相关的文档内容
知识库的数据可以来自于 Zion 数据库、API 以及本地上传
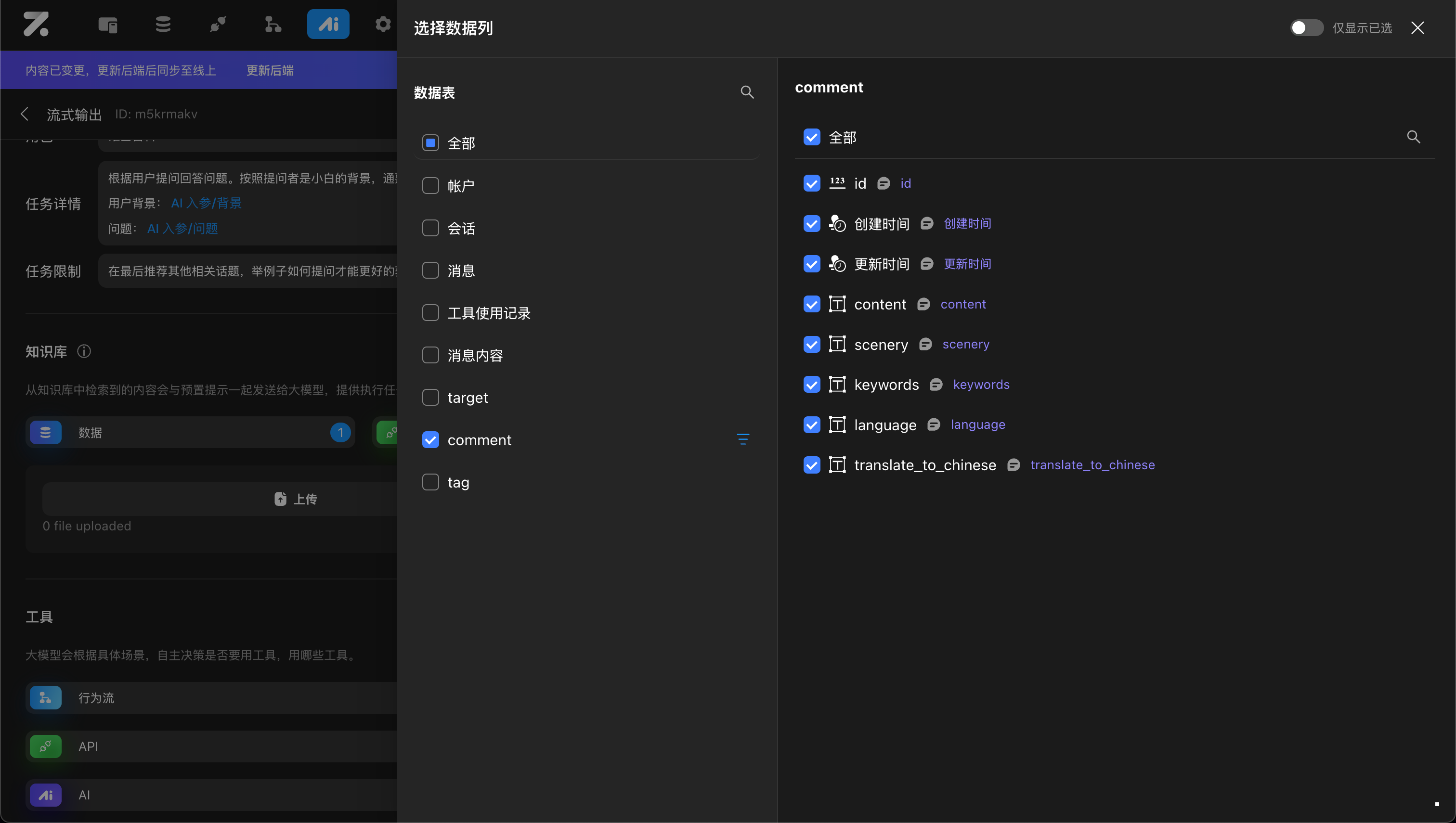
来自 Zion 数据库*
选择已经存储在 Zion 中的单个或者多个数据表、单个或者多个字段、关联表/关联字段,选择的数据表还能够预先做数据限额、过滤条件、排序以及去重的操作
读取的数据会直接给到大模型 ,从而消耗 Point ,所以在配置时建议控制读取的数据条数以及内容量,根据业务情况来设定数据限额,在避免超过大模型的处理限度的同时合理节约 Point 的使用
若想利用 RAG 给大模型提供私有知识,了解【数据向量化存储与排序】
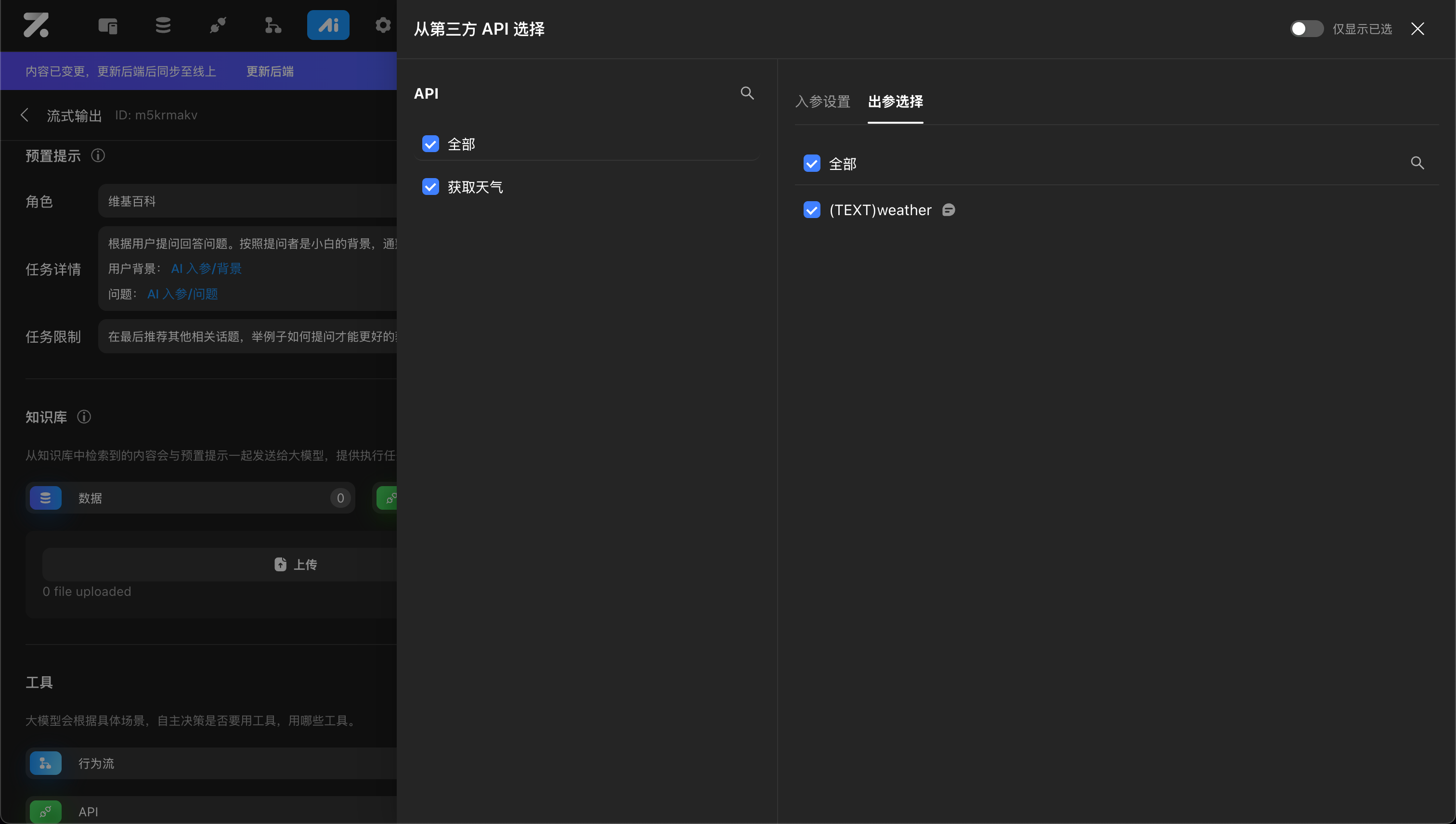
来自 API
即调用在 Zion 中配置好的第三方 API 获取到的数据,选择需要调用的 API 请求,设置对应的入参内容以及出参描述。了解【API 配置说明】
本地上传
选择本地文件上传到该 AI 配置,上传后的内容会自动进行分段、向量化处理,配置入参之后,会自动检索最相关的内容给到大模型作为上下文
- 目前仅支持 Word、PDF、txt、md格式的文件
- 文件总大小不超过50MB
工具调用
可以将 Zion 中的行为流、API,甚至另一个 Agent 作为该 Agent 的工具。在执行任务的过程中,它自主判断是否要用工具,用哪个工具。
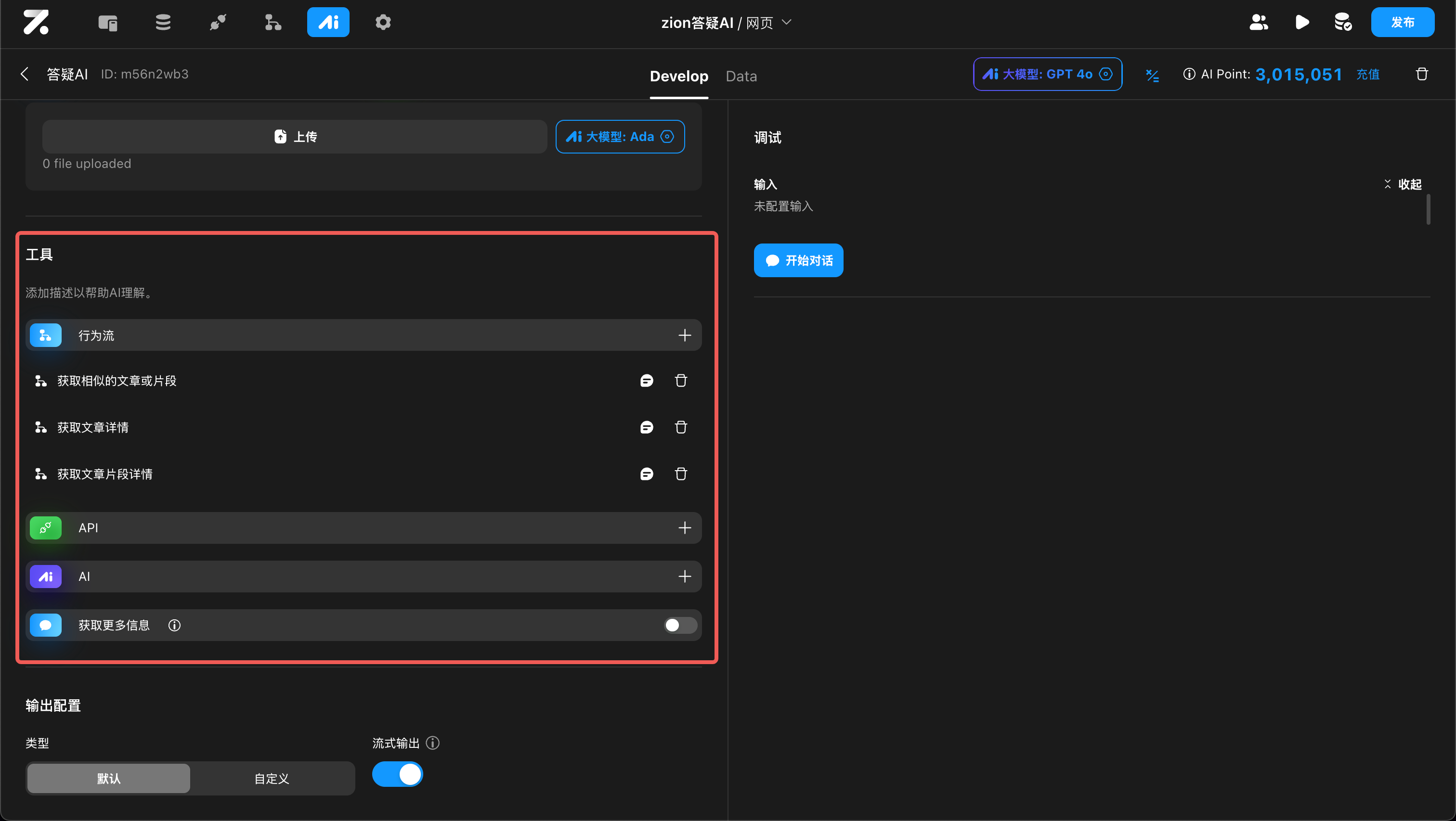
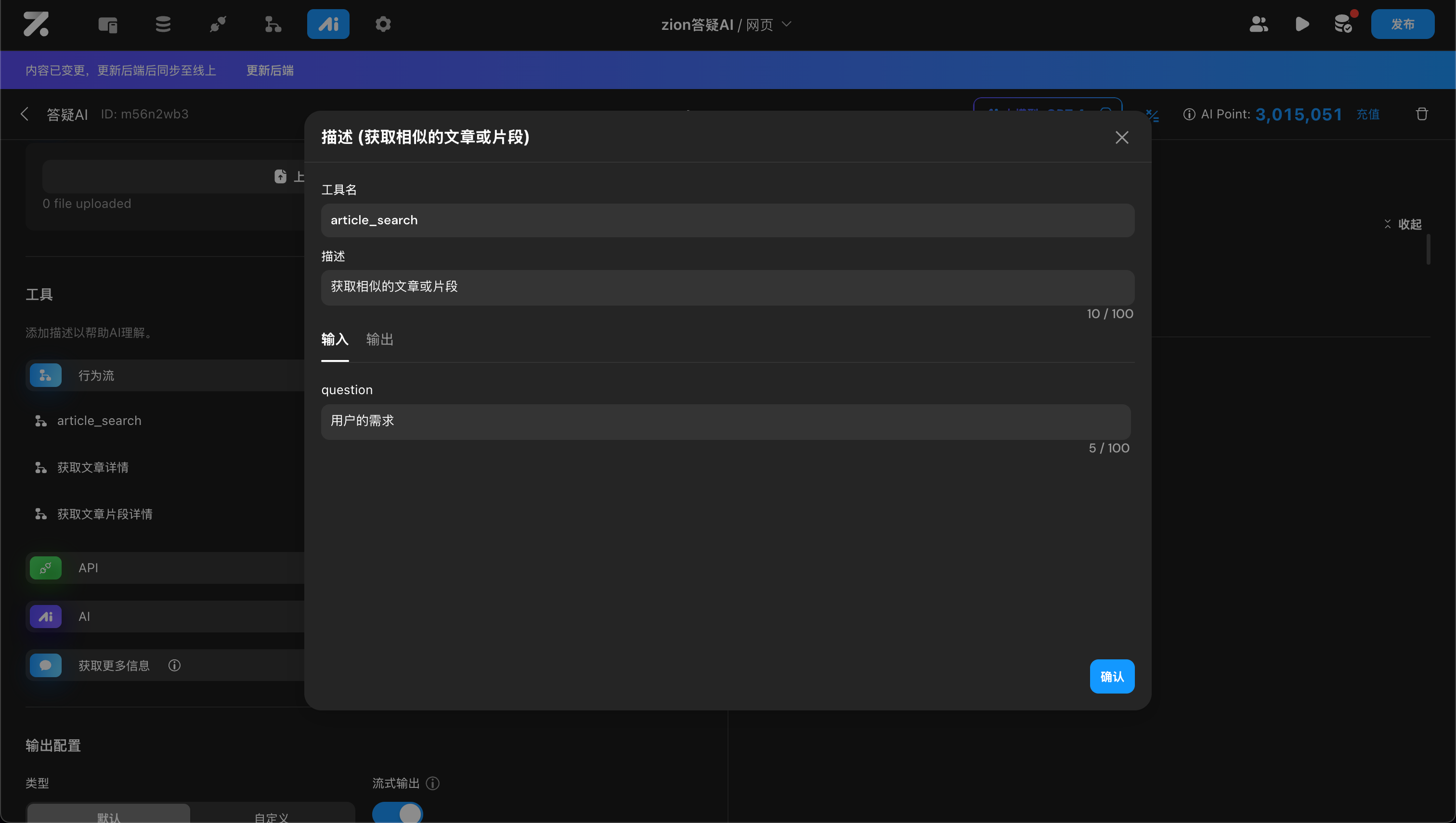
在使用工具时,大模型会根据情况自动生成该工具需要的参数;工具调用后,会自动将结果传送给大模型。良好的工具名和字段描述,可以帮助大模型更好地理解工具的用法,提高精准度。
输出配置
该配置主要是告诉大模型,以什么数据结构返回结果

默认: 不限制返回结果的结构。在这个模式下,才能够使用流式输出
自定义: 按照特定结构返回结果。如下图所示,以「JSON」对象的形式输出结果,每个字段均可添加描述,让大模型返回的内容更精准

调试
当完成了 Agent 的配置之后,可以在界面进行调试,查看运行效果
Agent 运行成功时,你可以检查输入、工具调用情况以及返回结果是否符合预期

使用 Agent 行为
Zion 提供了5种和 Agent 相关的行为

开始会话
用于开启多轮 AI 对话的首轮对话或者完成一次性对话。该行为调用成功后,会默认给大模型发送一条消息,然后返回会话id和大模型的返回结果,并在“会话表”中添加一条记录,在消息表中添加一条以system 为角色的消息记录。

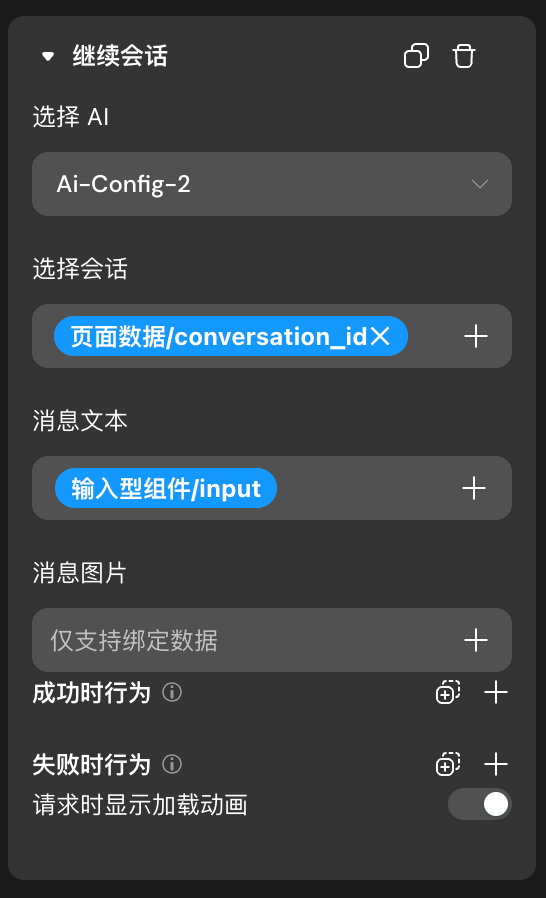
继续会话
在“开始会话”后,要继续给 Agent 发送消息时,则使用“继续会话”行为
在”继续会话“的行为中选择与上一次调用的”开始会话“相同的Agent ,并绑定“开始会话”返回的会话id。
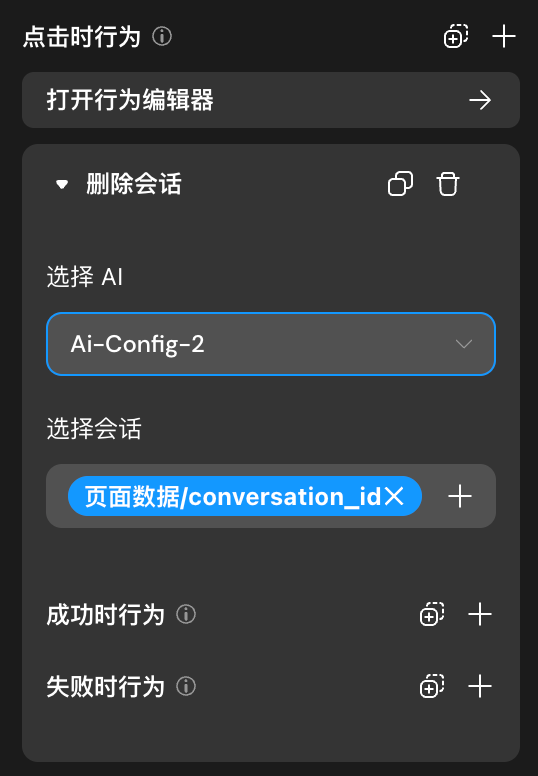
删除会话
删除会话的同时会删除与会话相关联的消息、消息内容、工具调用记录
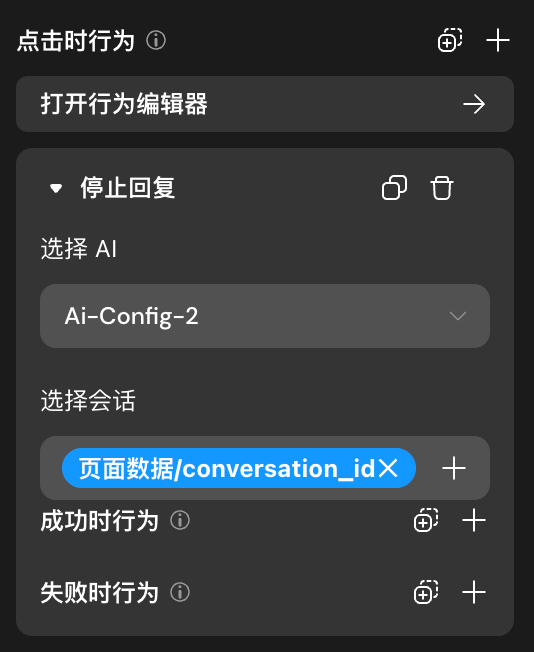
停止回复
“停止回复”即“开始会话”或“继续会话”过程中,会话还未结束,则可以触发“停止回复”停止当前对话,停止回复后,依旧可以使用“继续会话”继续刚才的多轮对话
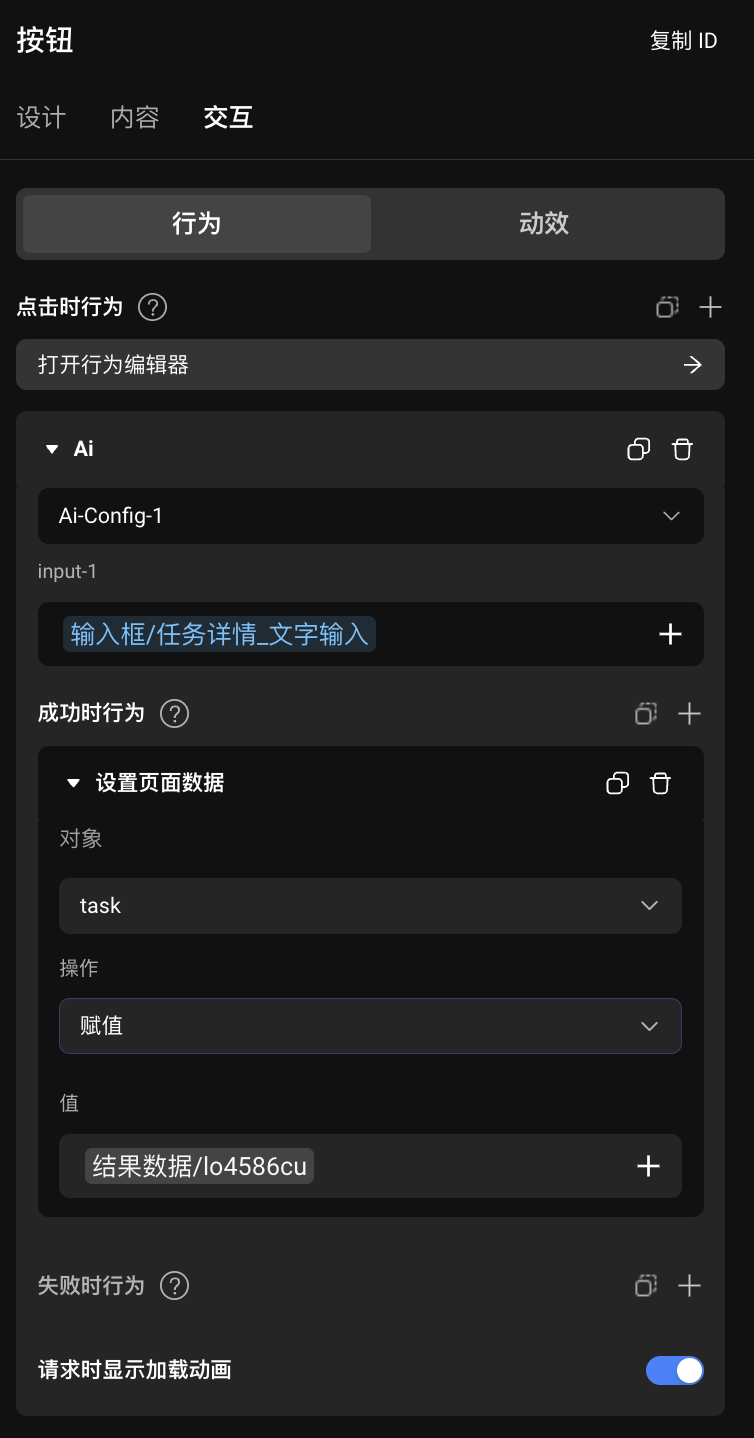
使用 Agent 的返回结果
默认输出时
为了直接显示 AI 请求回来的结果,一般在页面上添加一个页面变量,然后为按钮组件的点击时行为添加需要的 AI 请求,完成 AI 请求的入参配置,在其成功时设置页面数据,赋值为结果数据中的内容
| img | img |
|---|---|
 |
 |
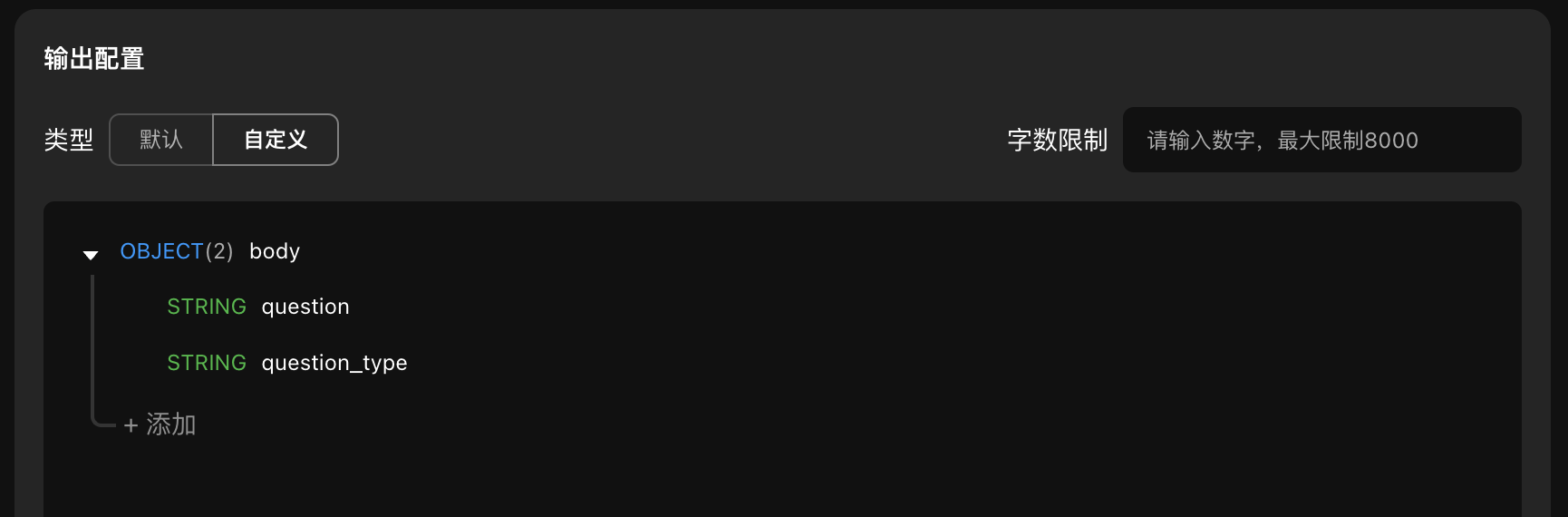
自定义输出时
当配置 AI 时,配置了自定义输出,你将需要按照如下格式设置输出的字段类型、名称(一定要是英文,最好是能够与你期待的输出结果意义相同的英文单词或短句),AI 将会按照字段名称把对应的结果写入到该字段中
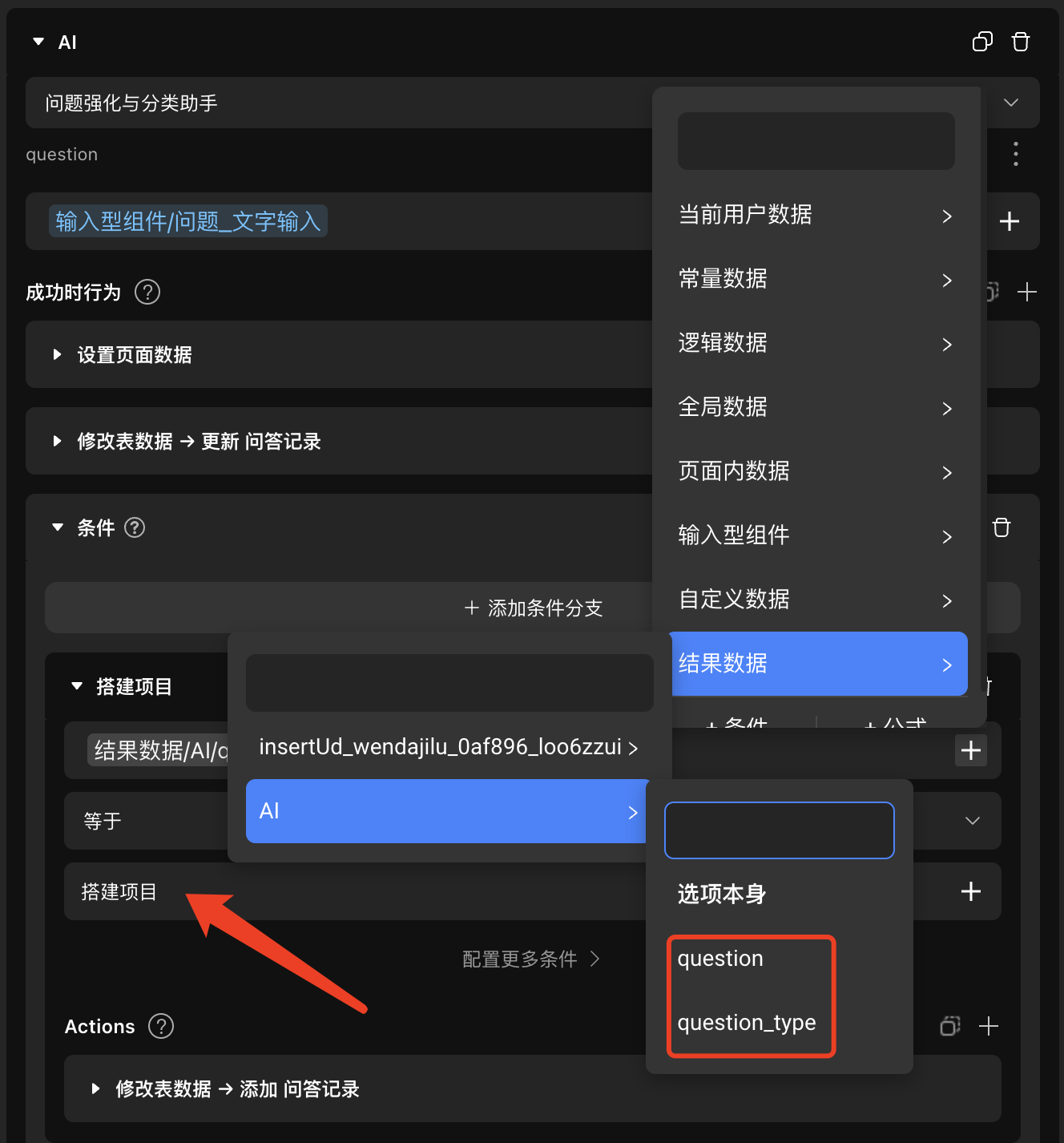
在调用该 AI 时,你将可以在 AI 结果数据中选择需要引用的字段内容,例如下方案例中是将 AI 返回的问题类型数据 question_type 与「搭建项目」进行比较
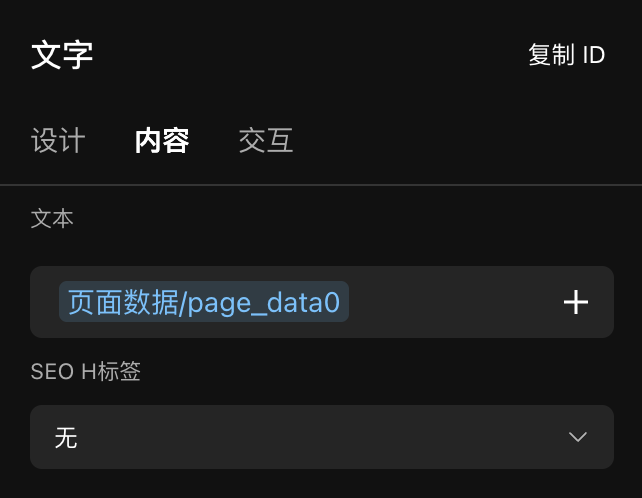
流式输出时
当配置 AI 时,打开了「流式输出」的模式,那么在调用 AI 时,会出现「将流式输出数据赋值给」的配置,在配置中需要选择事先在页面中创建好的页面数据进行赋值,而后可将该页面数据绑定给【文字组件】,当 AI 调用成功时,文字组件就会将结果以流的方式进行输出呈现
 |
 |
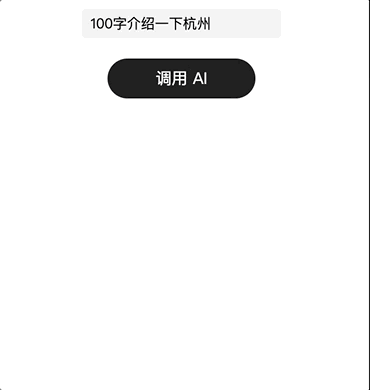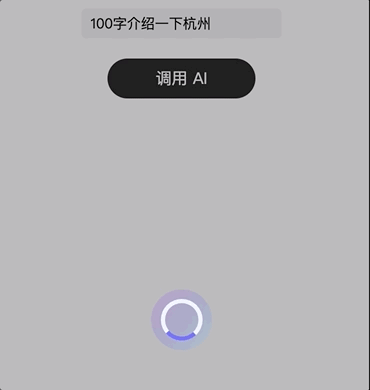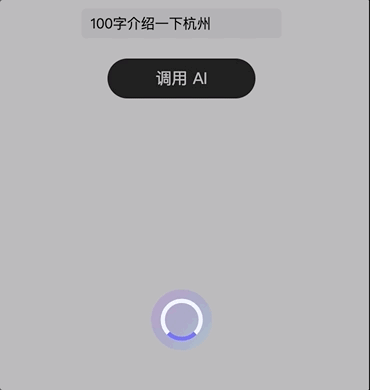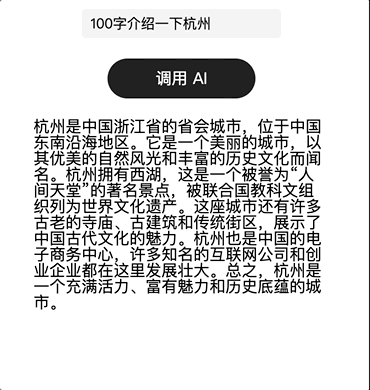 |
请求时显示加载动画: 默认打开,发起 AI 请求时,在请求结果回来之前显示如下加载动画
