数据向量化存储与排序
应用背景
大模型的相似度计算是在海量的非结构化数据里找到更相似的数据,这时候需要向量数据库来存储每个对象的信息 如果您的项目需要使用到“相似性搜索”功能或者需要通过 RAG 的方式给大语言模型提供搜索结果的话,在保存数据时,需要将其保存为向量数据
如何保存向量数据
进入编辑器之后,点击左上角的【数据】按钮打开数据模型设计界面,创建一张数据表,为这张数据表添加字段(即添加列),用于保存需要进行向量化处理的文本数据,类型为“文本”
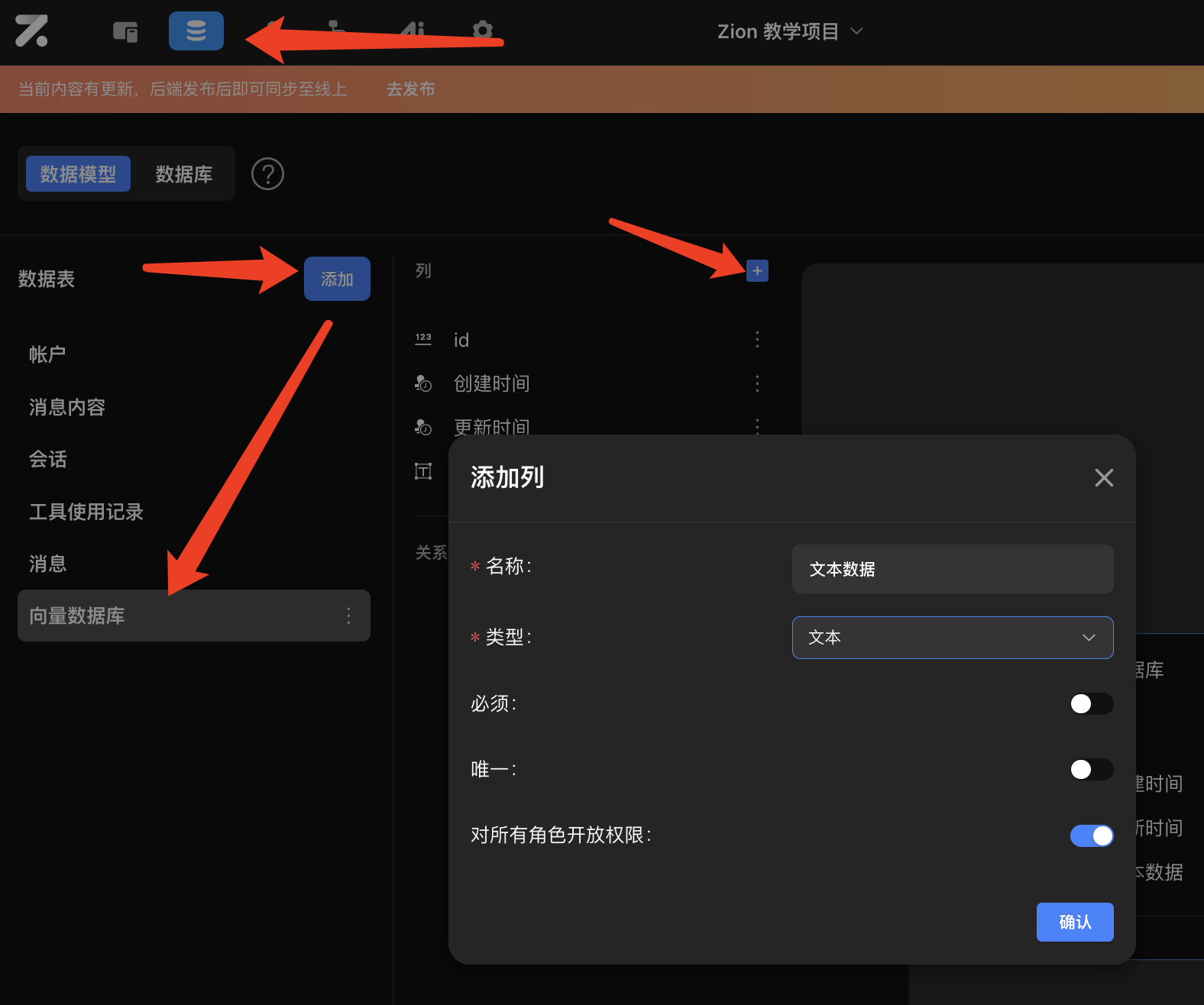
点击添加新的字段后的设置按钮,点击【打开向量存储】,往后保存在该字段下的数据将被向量化处理
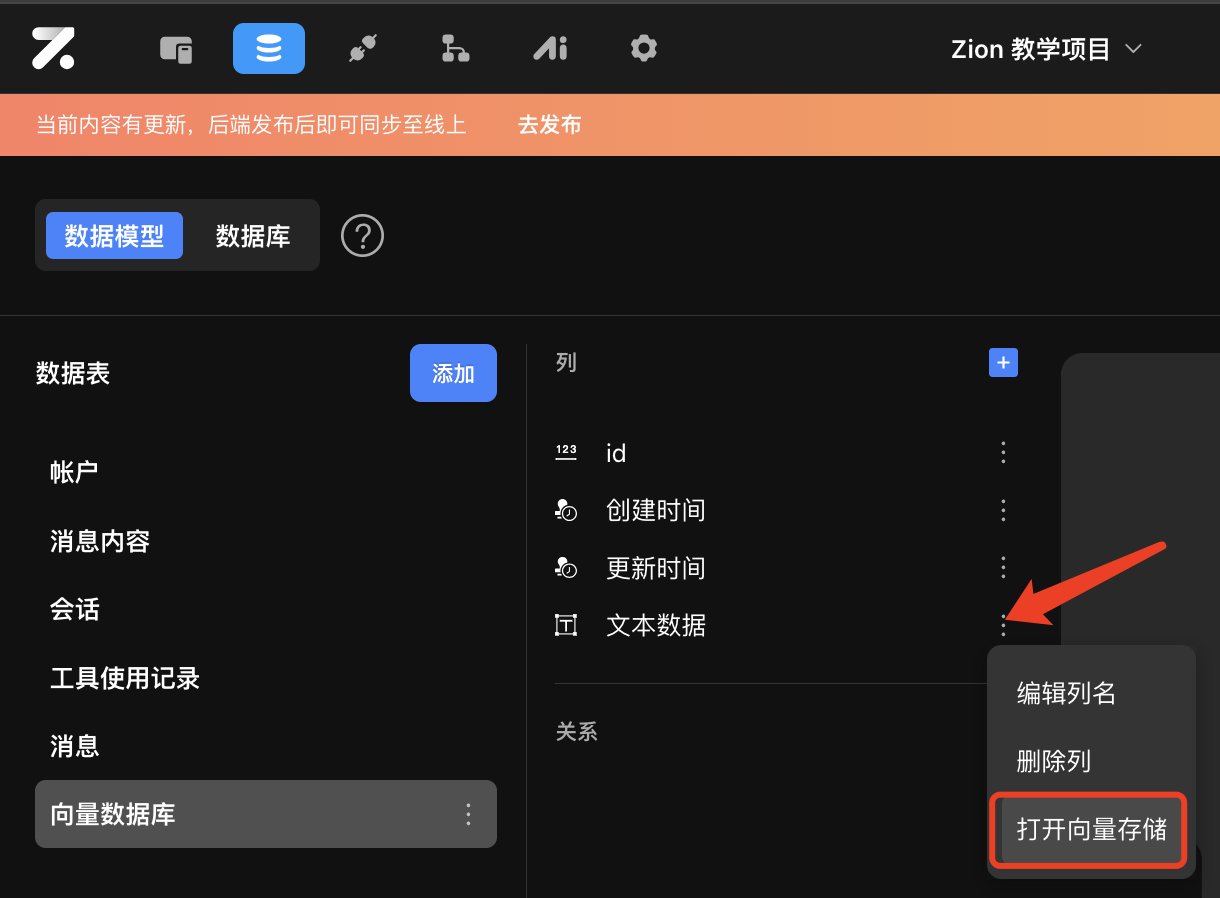
⚠️ 注意:
- **目前 Zion 仅支持将文本数据存储为向量数据。** - **该功能打开后会消耗一定的数据库用量**什么是向量排序
向量排序基本原理:根据「排序对象」与「对比对象」的向量距离远近进行从小到大的排序,距离越近,表示「排序对象」跟「对比对象」的相似度越高,也就会排在越前面
Zion 提供的向量距离的计算方式有两种: COSINE(余弦距离)与 EUCLIDEAN(欧式距离)
- EUCLIDEAN 适用于需要衡量绝对差异的场景,关注点在于数值大小和具体的物理距离。例如:导航系统、物流配送路径优化;比较不同时间段的生理参数(如心率、血压)变化。
- COSINE 适用于需要衡量方向相似性的场景,关注点在于相对关系和方向一致性。例如:搜索引擎、文本分类、推荐系统。## 在列表组件中进行向量化排序
应用场景
如下方所示的搜索场景,基于数据向量化之后,通过在输入框输入内容之后,通过向量排序的方式将相似的内容展示出来。常见的如药品搜索、五金工具搜索,由于常人可能只能描述这个药品或者是工具的具体使用场景,但无法明确的说出药品或工具名称,则可以利用相似性搜索来实现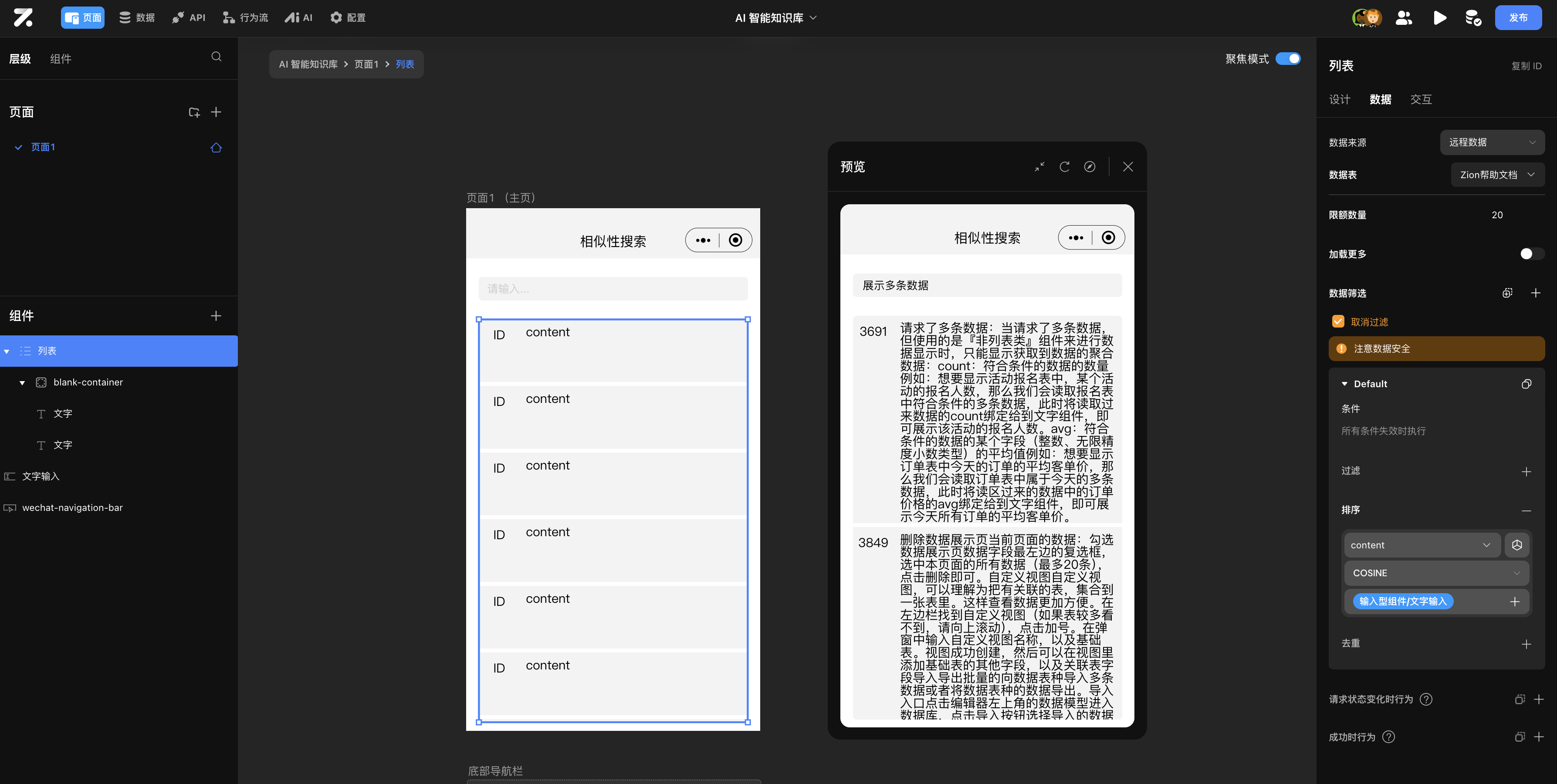
配置方法
- 为【列表】组件绑定带有向量字段的数据表
- 在【列表】组件的「排序」中选择转换为「向量数据」的字段,而后会出现并选择「向量」的排序模式
- 选择向量距离的计算方式
- 绑定「对比对象」的值
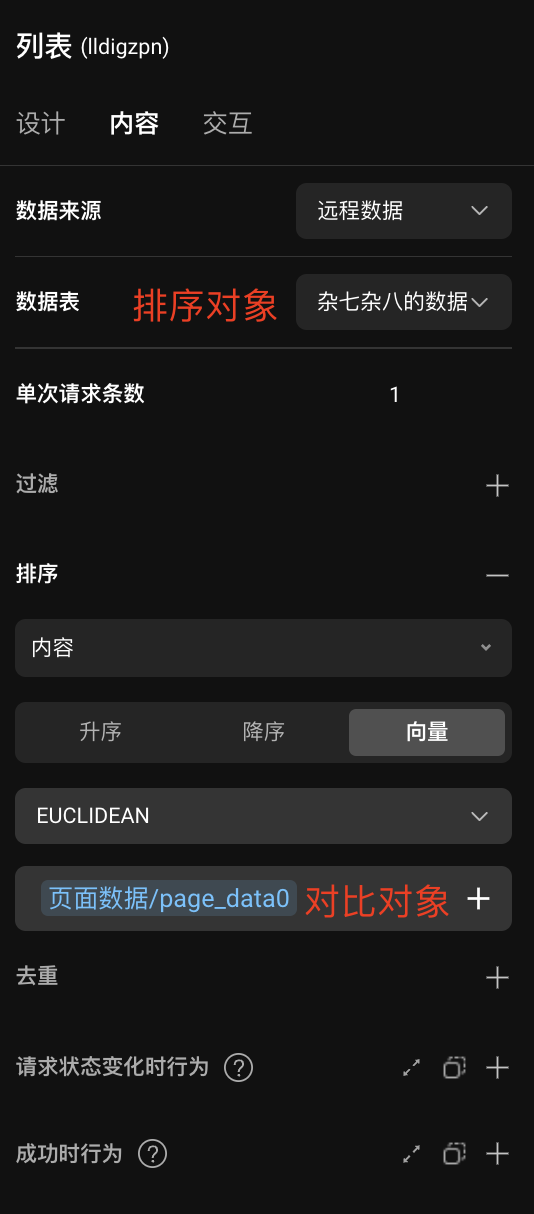
在 ZAI 中绑定数据库进行向量化排序
应用场景
在使用大语言模型时,可以通过 RAG 的方式让大语言模型基于私有化知识内容来完成更多内容的内容交互,如基于私有知识库回答问题,基于私有知识内容生成新的内容等
配置方法
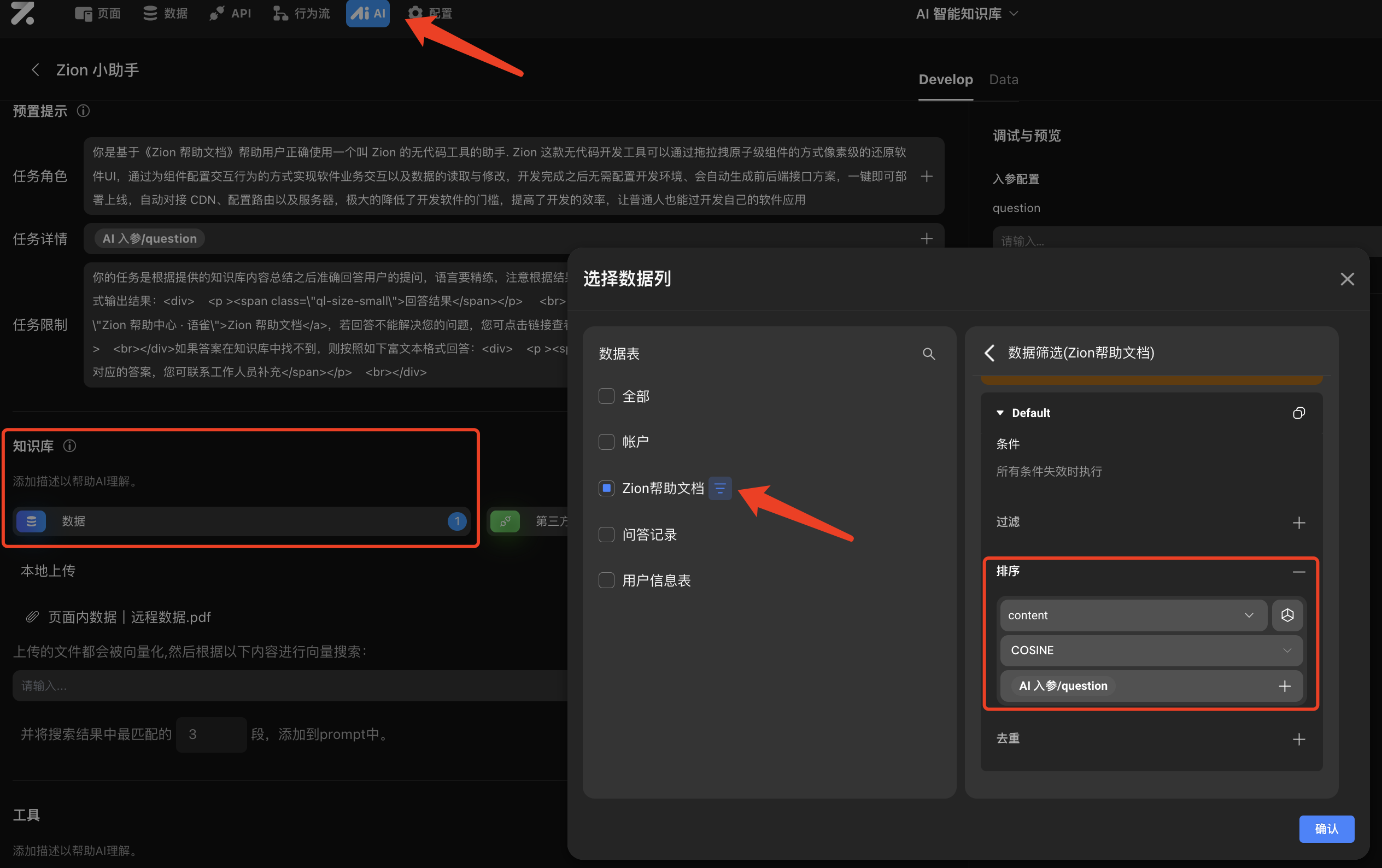
配置前提: 创建了保存私有数据的数据表,表中的文本类型字段开启了向量存储 配置步骤: 点击知识库下的数据,选择数据表,点击数据表旁的筛选按钮,在右侧的配置栏中添加【排序】配置,从上往下依次为:排序字段(为该数据表中进行了向量化处理的字段),向量排序方法,向量排序的对比内容
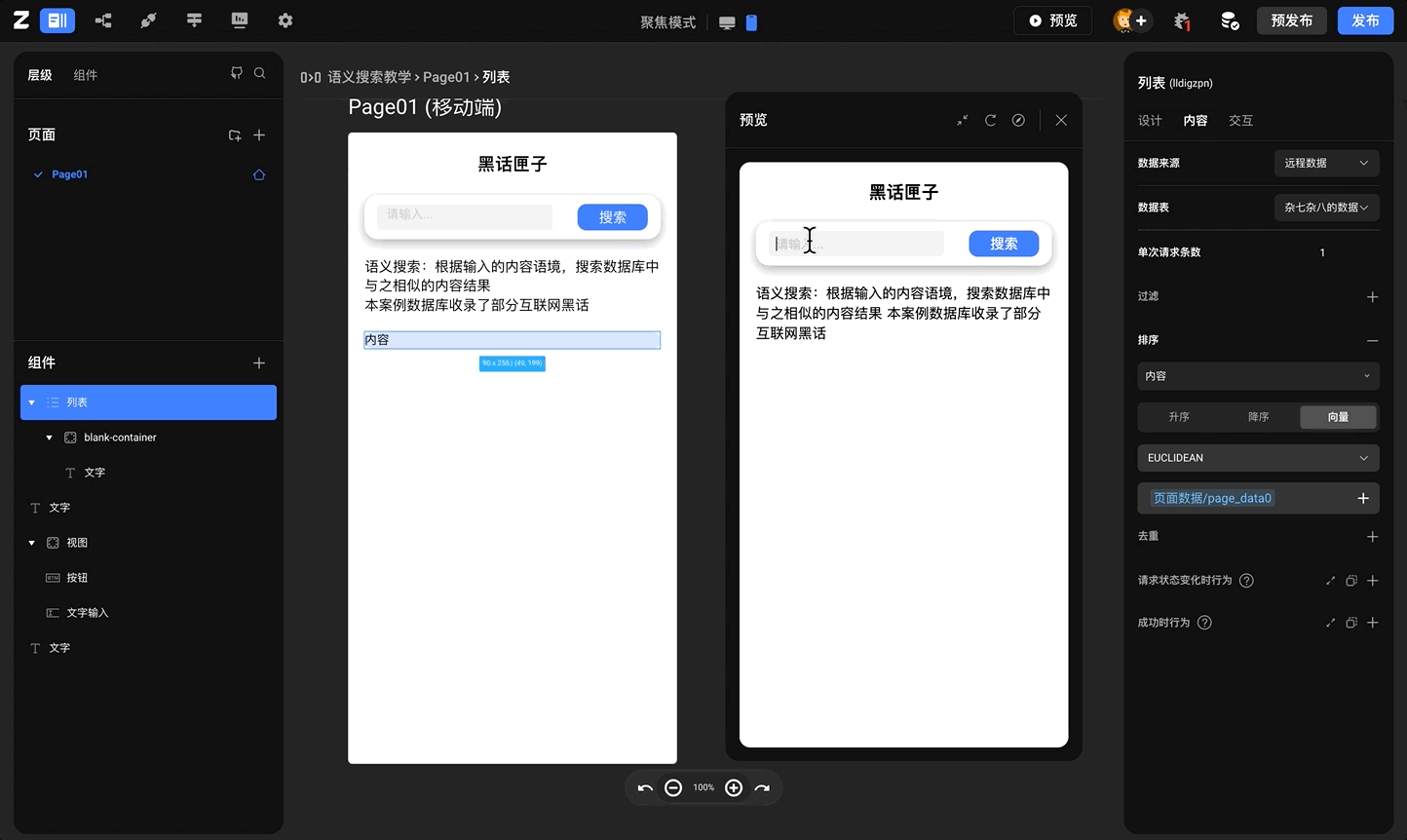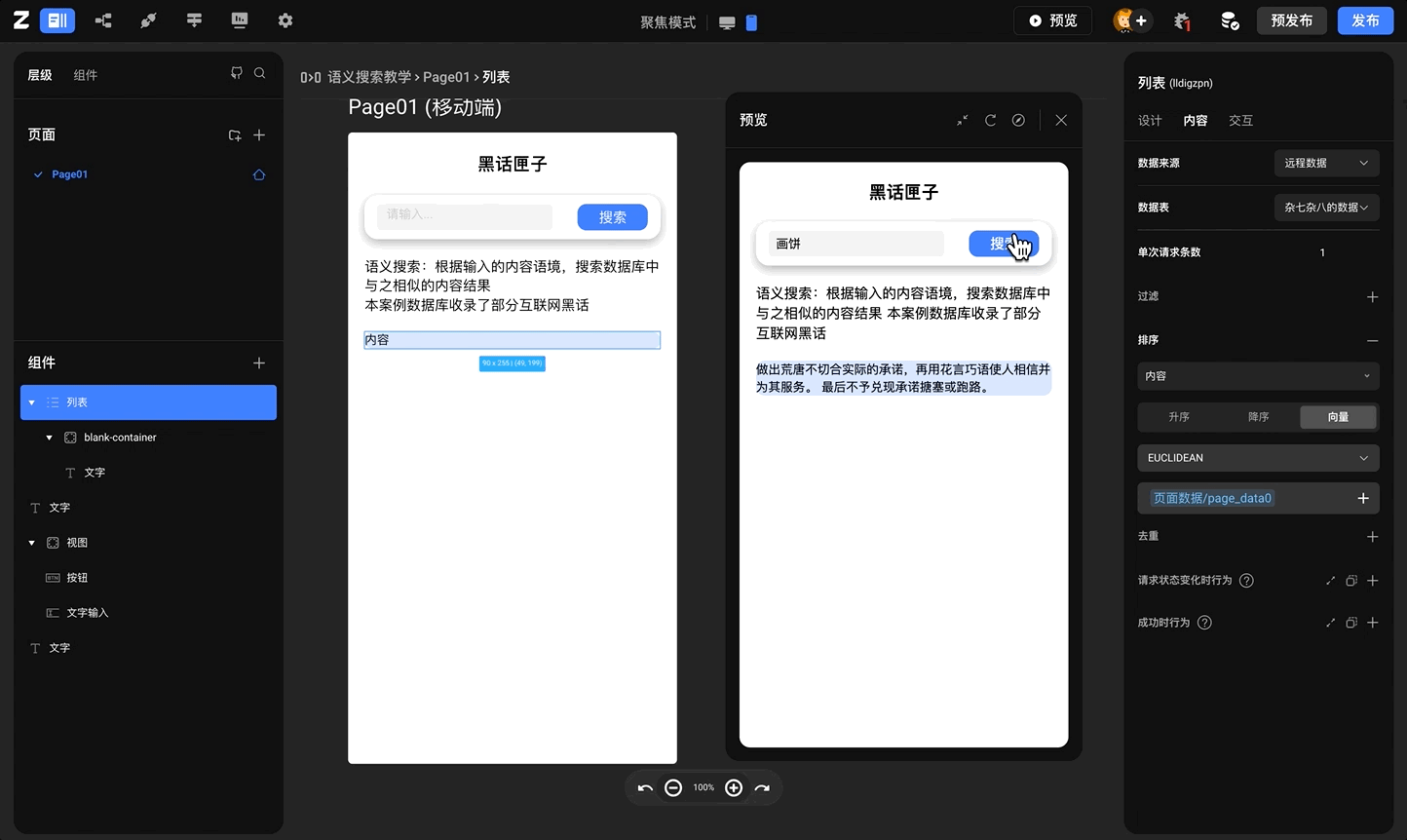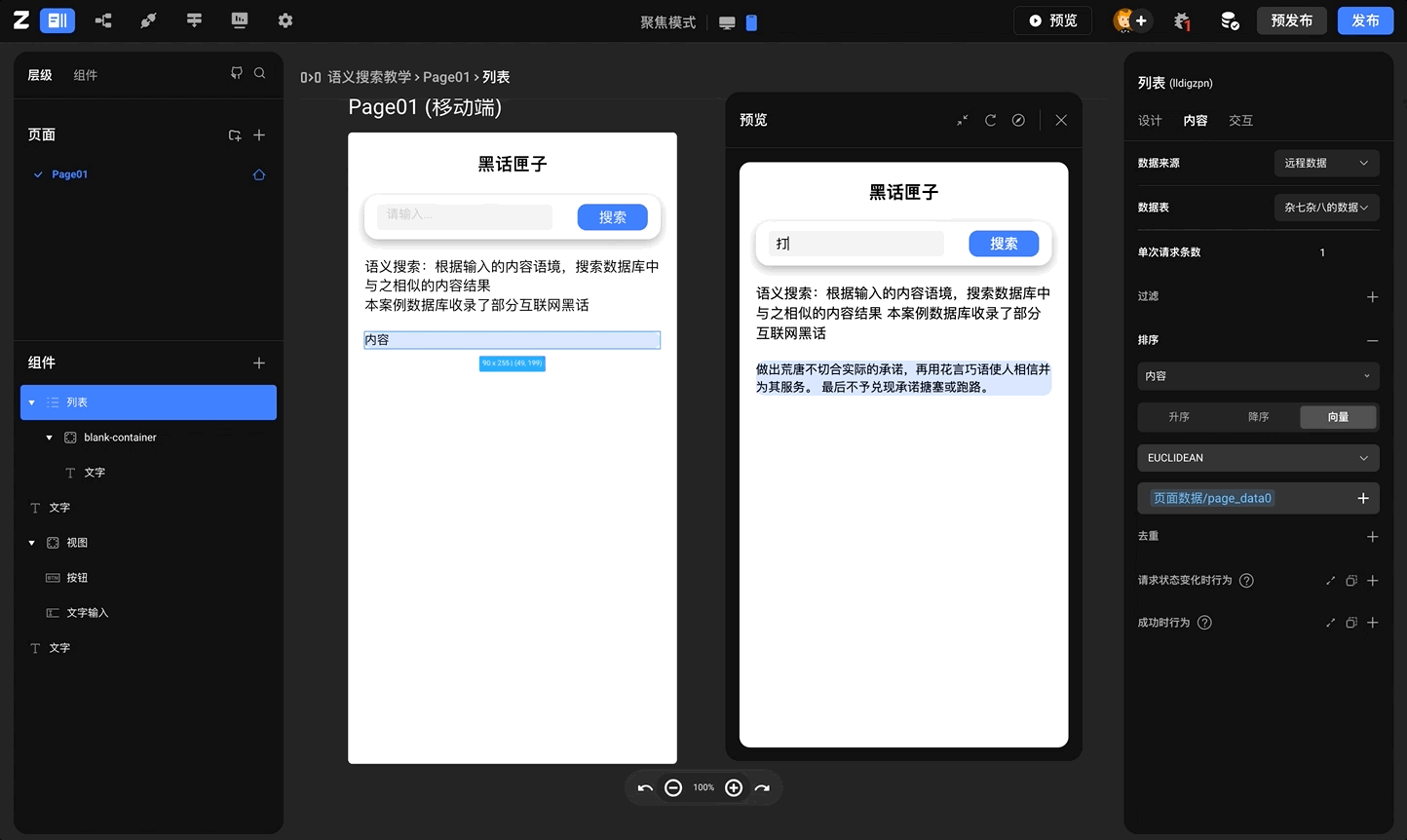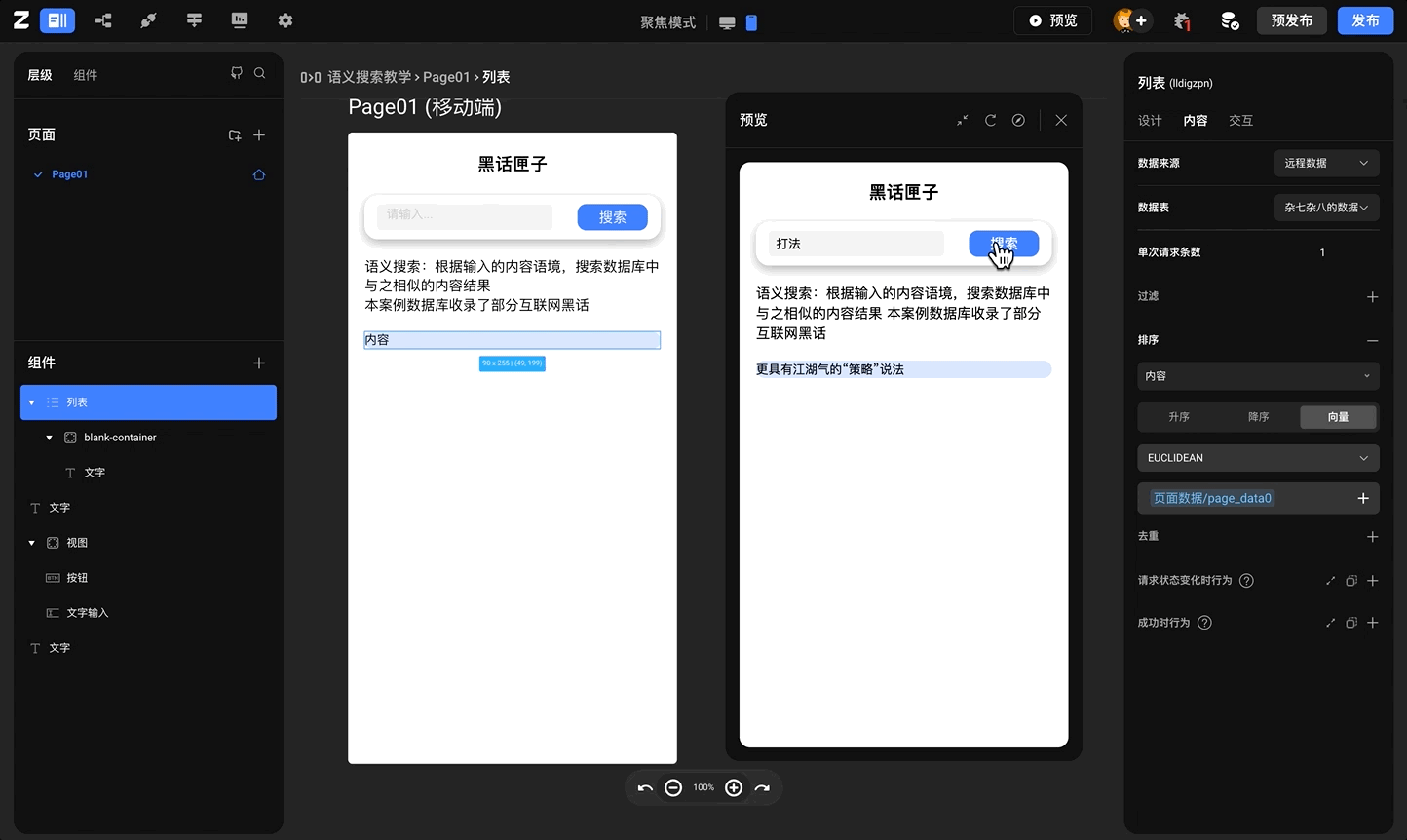
应用实例 - 语义搜索
案例基本描述: 案例数据库中收录了一系列互联网黑话的具体含义,通过互联网黑话来搜索其具体含义,在本案例中,向数据库中上传的互联网黑话内容将会被转化为向量数据,在搜索框中输入的内容也会被转换为向量数据,在点击搜索按钮之后,【列表】组件返回的将会是向量距离对比以及经过排序之后的结果 互联网黑话参考链接【互联网黑话收录】
案例效果: