数据模型概念
为什么要设计数据模型
由一张或者多张数据表(你可以想象就是一张张Excel表),数据表之间建立了引用关系的就叫做数据模型,开发应用软件之前,设计合理的数据模型能够让开发效率事半功倍! 在设计应用软件时,需要考虑应用需要呈现哪些数据或者保存哪些用户的交互数据,这些数据需要保存在哪些表中,每张表中有哪些数据字段(表头),表与表之间是否有引用关系,此时需要设计数据模型来明确数据表、数据字段以及表关系。 创建了数据模型之后,相当于定义了保存数据的数据表的形式。
什么是数据表
数据表是明确规定了字段名称、字段类型,每一行数据都严格按照字段顺序与类型记录的表。更进一步的,数据表一般会有一个无意义的、静态的字段来为每条数据编号,这个字段被称为主键字段。在大多数表中,会将主键字段命名为“id”,id 的特性是一个随着数据量增加而自增的一个整数。 成绩表A
| id | 姓名 | 班级 | 科目 | 成绩 |
|---|---|---|---|---|
| 1 | 小明 | 1班 | 语文 | 98 |
| 2 | 小明 | 1班 | 数学 | 78 |
| 3 | 小明 | 1班 | 英语 | 85 |
| 4 | 李雷 | 2班 | 语文 | 88 |
| 5 | 李雷 | 2班 | 数学 | 77 |
| 6 | 李雷 | 2班 | 英语 | 100 |
| 7 | 韩梅梅 | 1班 | 语文 | 30 |
| 8 | 韩梅梅 | 1班 | 数学 | 30 |
| 9 | 韩梅梅 | 1班 | 英语 | 30 |
如上表,该表的字段有id、姓名、班级、科目、成绩 5个,其中id为该表主键,姓名、班级、科目是文本字段,成绩为数字字段。表格的9条数据,每一条数据都严格按照这几个字段的先后顺序、类型记录了各字段下的值。比如,成绩字段中就不允许出现“不合格”这样的文本值。
区分什么是“坏的”的数据表
在知道数据表会经常遭遇统计需求后,我们来区分什么是坏的数据表。 成绩表B
| id | 姓名 | 班级 | 语文成绩 | 数学成绩 | 英语成绩 |
|---|---|---|---|---|---|
| 1 | 小明 | 1班 | 98 | 78 | 85 |
| 2 | 李雷 | 2班 | 88 | 77 | 100 |
| 3 | 韩梅梅 | 1班 | 30 | 30 | 30 |
【表B】和【表A】的信息量是一致的,但是为什么要将其称为“坏的”数据表? 因为一般而言,我们会要求数据表在设计好后就尽量少的改动自身的字段结构,表B的设计延展性不够强,会导致遭遇后续的新需求时要对数据表的维护升级工作成本更高。 比如,后续的考试增加一个新科目 “物理”,在【表A】中我只需要在记录每个人的成绩时多记录一条科目=物理的成绩即可,而【表B】我则必须要去为整张表增加一个字段。 更抽象地说:在承载相同信息量且无重复信息的情况下,一张数据表的字段设计,应该以数据条数最大化为原则。
为什么要拆分数据表并建立数据关系?
在上一阶段我们讨论了【表B】是不合格的,这一阶段我们要进一步指出:【表A】其实也是不合格的。 可以假象几种情况: 如果某名同学发生了转班,那么【表A】原先所记录的该同学的班级就是错误的,必须要统一进行修改; 如果某个科目改了名(比如“英语”改为“外语”),那么【表A】的记录同样会出错需要修改; 又如要从【表A】中统计每个班级有几个人,也许可以对姓名去重后,以班级为分组字段统计计数量。但这也未必能得到真实的数据:可能有人缺席了这次考试、可能有人在这次考试后退学/才刚入学。 总之,成绩表尽管有人员字段,但其延展性依然成问题,无法准确记录人员、科目的变化情况。 这个意义上,我们需要拆分数据表,以应对更全面和深入的需求。 (拆分数据表的另一个核心作用是减少调用数据时对服务器的压力,这点不做展开) 比如【表A】就理应被拆分为人员表、科目表以及成绩表 (可以进一步拆分班级表,但因为班级相对比较固定,不进行该操作) 。 人员表person
| id | 姓名 | 班级 |
|---|---|---|
| 1 | 小明 | 1班 |
| 2 | 李雷 | 2班 |
| 3 | 韩梅梅 | 1班 |
科目表course
| id | 名称 |
|---|---|
| 1 | 语文 |
| 2 | 数学 |
| 3 | 英语 |
但是一个问题是,从成绩表拆分出人员、科目后,成绩表现在应该变为什么样?如果没有了姓名、科目字段,要如何确定每个成绩的记录是哪个科目哪个人员的? ——通过建立关系,也就是在成绩表中插入对应的人员表id和科目表id: 成绩表grade
| id | person_id | course_id | 成绩 |
|---|---|---|---|
| 1 | 1 | 1 | 98 |
| 2 | 1 | 2 | 78 |
| 3 | 1 | 3 | 85 |
| 4 | 2 | 1 | 88 |
| 5 | 2 | 2 | 77 |
| 6 | 2 | 3 | 100 |
| 7 | 3 | 1 | 30 |
| 8 | 3 | 2 | 30 |
| 9 | 3 | 3 | 30 |
我们可以通过person_id查询人员表的信息,通过course_id引用course表的信息,从而让成绩表grade承载的信息量和成绩表A完全一致。 建立关系的本质是使对方表可以引用当前表的数据,而数据模型,就是带有关系的数据表。关系主要以1:N(一对多)关系为主,1:1查漏补缺用。
数据模型关系
1:1(一对一)关系
如果表A与表B建立了1:1关系,A表中的某一条数据只跟B表的某一条数据相关联。 比如我们有一张很大的用户信息表,由于字段过多,不方便管理,于是根据业务需求将其拆分成了A、B两张表,其中A表为user表,B表为user_auth表,user表主要存放的字段为用户基本的信息(用户ID、真实姓名、昵称、真实头像、性别、职位、教育程度、专业、创建该用户的时间等),而在user_auth表主要用存储验证用户的信息(用户ID、用户密码、邮箱、手机号等信息。) 1:1关系实际上就是将一张较大的表但是这些数据字段不容再拆分时,拆分成了两张或者多张表,通过1:1的关系相关联,方便数据的查询以及管理。
1:N(一对多)关系
如果A表对B表建立了1:N关系,我们将A称为B的上级表,比如上面的学生表对学生成绩表就建立了1:N关系。 建立关系的本质,是在下级表中插入一个记录上级表id的字段,表示这个下级表条目属于哪个上级表条目,比如学生成绩表的该条数据:
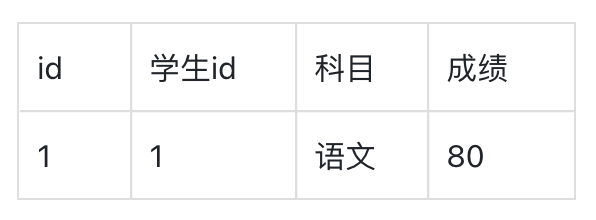
就表示其属于学生表中id=1的条目,也就是林总的成绩

我们一般将N表中表示1表id的字段称为外键。在zion中建立关系后,会自动在下级表中添加外键。 那么,如何判断两张表是否要建立关系、以及怎么建立关系呢?
- 从属视角
亦即判断:B表条目是否只能从属于一条A表条目,如是,则A表对B表可建立关系。 比如 一个学生只能在一个班级内,而一个班级里有多个学生,那么班级对学生就可以建立1:N关系; 又比如一条学生成绩只能从属于一个学生,而一个学生可以有多条成绩记录,那么学生表对学生成绩表就可以建立1:N关系。
- 引用视角
N表可以通过关系引用到1表的信息。可以将关系看做是一扇门/一个链接,通过这扇门N表可以找到对应1表的信息。 对应在 Zion,这种引用体现为建立关系后,绑定时出现的侧拉框。比如,我在学生成绩列表中,想知道各条成绩对应的学生的学号:
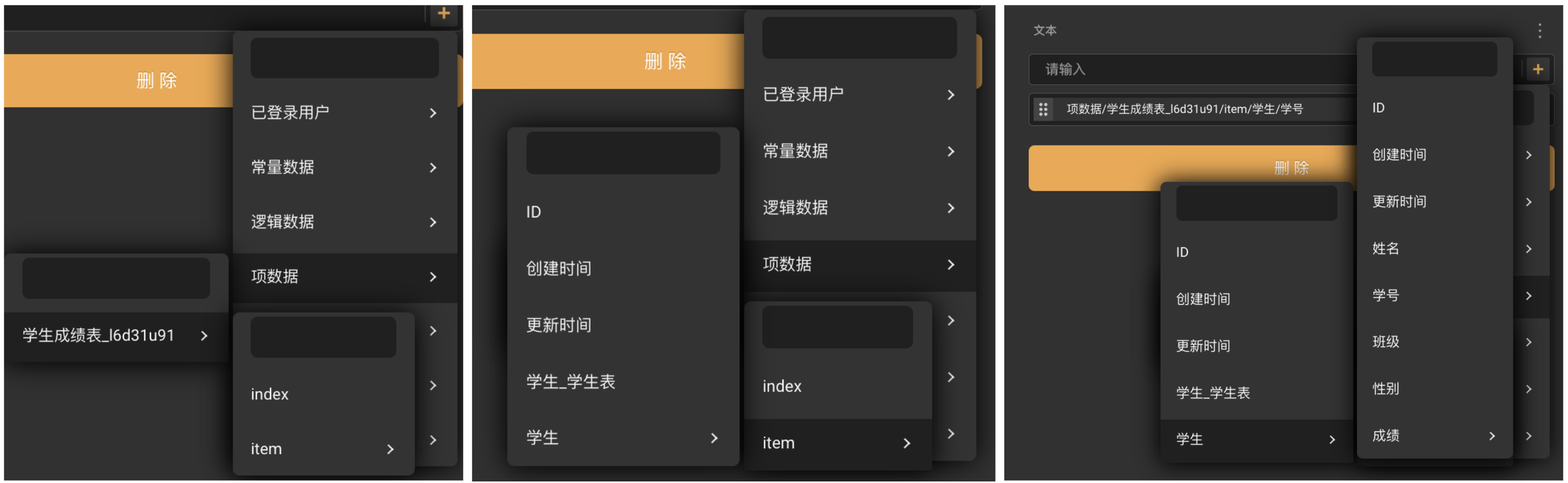
当涉及复杂数据模型,对关系感到混乱时,也可以从引用的角度进行思考:这张表需要哪些信息?哪部分信息是其他表中就已经有了的?这些信息可以通过关系引用得到,那么怎么建立关系才能做到这点?
特别的 1:N 关系:自关联表
自关联指数据表自己对自己建立了一对多关系,通常运用在带有层级结构的信息中 在电商案例中,“分类”就是一个自关联表,通过“父级分类”来确定自己的上级分类是什么。
并且通过这一个关联字段就可以添加更多的层级。

除了分类,其他的常用场景有:
- 公司员工层级
- 游戏任务线
- 内容下一页### 特别的 1:N 关系:双关联表 被引用的对象向引用方建立2个关系字段的架构,典型的运用场景是聊天数据模型被引用对象为用户,引用方是聊天消息。 聊天消息数据表中引用两次用户表的id,分别用来表示发送消息的用户和接收消息的用户

“sender_id”是发送消息的用户,“receiver_id”是接受消息的用户
N:N(多对多)关系
有时我们会遇到两个实体之间存在多对多关系的情况,比如 报名(例:用户表,活动表,用户可以报名多个活动,一个活动也可以被多个用户报名) 收藏(例:用户表,商品表,用户可以收藏多个商品,一个商品也可以被多个用户收藏) 点赞(例:用户表,文章表,用户可以点赞多篇文章,一篇文章也可以被多个用户点赞) 这种情况下,我们会采用在两个实体表之间建一个中间表,然后让两个实体表分别对其建立1:N关系,来实现两个实体多对多关系的实现。以活动报名为例:
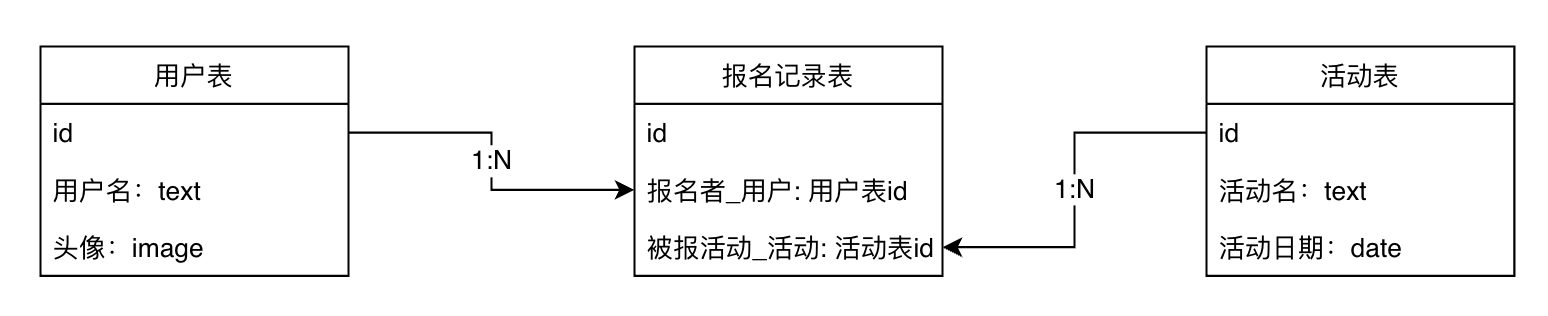
其他类似的常用场景有:
- 活动报名
- 图书收藏
- 视频点赞
- 内容标签# 什么是统计表?数据表和统计表的意义是什么 统计表是对源数据表进行统计后产生的表,统计表没有主键,其他的记录原则和数据表一致。 比如针对上一节的成绩表,我想知道各班级各同学的总分情况,那么可以得到如下的统计表:
| 班级 | 姓名 | 总分 |
|---|---|---|
| 1班 | 小明 | 261 |
| 1班 | 李雷 | 90 |
| 2班 | 韩梅梅 | 265 |
统计表会有明确的分组字段 (黄色表示) 和统计字段 (无底色表示) ,一个统计字段只能由源数据表的单个字段统计得到,可执行的常见的统计操作一般有计数、求和、求平均、最大值、最小值几种。数据表的信息对于一般人而言太多太杂,提炼出针对性的统计表是非常常见的需求。 对于初学者,一个典型的场景是:在没有任何源数据表的情况下,我接到一个统计需求,我可以直接绕过数据表,直接制作统计表吗? 回答是不建议。统计过程,本质是提炼信息的过程,这个过程会损失信息量。比如仅看总分统计表,我们无法知道每个人各科的成绩是什么,甚至不知道有哪几门科目。这样在下一次遭遇其他的统计需求时,我们可能就无法满足,比如,各科成绩的平均分情况。 因此标准的流程是,先数据采集做出数据表,再通过数据表统计出统计表。